강화학습 매매 프로그램을 만들면서 프로그래머로써 가장 큰 도전을 견뎌야 했습니다. 학습량이랑 소스, 디버깅 량 시스템 투자 모두 역대 최대였습니다. 중간쯤 진행하다보니 포기할 수가 없었습니다. 이 글은 다른 도전자에게 대한 삽질의 최소화를 도모하고자 작성하게 되었습니다. 부디 이 글을 읽으시는 분들은 좀 더 들 고생하였으면 합니다. 개발 환경은 win10(wsl 개발환경으로 변경)에 메모리 48G CPU는 제온 2650 V3에 RTX 3060 OG 12G 2장과 화면 디스플레이용 RTX 1060한장이 들어간 시스템을 사용했습니다. 꼭 이렇게 할 필요는 없지만 DQN은 CNN을 베이스로 하므로 GPU 메모리를 굉장히 많이 사용합니다.
딥런닝 엔진으로 PYTORCH를 사용했지만 tensoflow로 변경은 그리 어렵지 않을 것으로 생각됩니다. 먼저 머쉰런닝을 공부한 경험이 있는 사람은 지도 학습과 비지도 학습에 대한 내용은 어느 정도 알고 있을 것으로 생각합니다. 지도 학습은 기존에 정재된 데이터가 이미 존재하고 데이터에 대한 결과가 분명할 경우 학습을 통해 새로운 데이타를 분류하거나 값을 예측하는 것을 말합니다. 예를 들면 한 고등학교 학생을 대상으로 방과후 학습시간을 설문 조사한 후 3번의 시험을 치고 나서 4번째 시험 결과를 예측하는 경우가 지도학습과정이라 할 수 있습니다. 비지도 학습은 데이터는 존재하지만 분류기준등이 모호할 경우 머쉰런닝을 통해서 분류값을 얻고 데이터를 분류하는 경우입니다. 예를들면 어느 들판에 있는 들꽃을 조사했는데 같은 종류지만 키가 차이가 나는것을 발견하고 머쉰런닝을 돌려서 같아보이지만 다른 종류의 꽃이 몇가지가 존재하는지 예측하는 프로그램을 만들었다면 그것은 비지도 학습입니다. 그렇다면 다음은 어느경우에 해당할까요? 한국어를 학습하는 머쉰런닝 프로그램이 있다면 프로그램은 무작위로 학습해서 주어와 동사가 있다는 것을 학습한 후 언어에는 순서가 있다는것을 배우고 그후에는 사람과 실시간 채팅을 학습합니다. 사견이지만 지도학습과 비지도학습은 머쉰런닝을 설명하기 위한 기준이지 강화학습으로 들어가면 분류 자체가 무의미해지는 것 같습니다. 강화학습을 가장 쉽게 설명하는 것은 영화일것 입니다. 그것도 타임 루프물 영화들이 그렇습니다. 톰 크루즈가 출연한 작품 중 '엣지 오브 투모로우'라는 영화가 있습니다. 이 영화는 외계 생맹체로 부터 지구가 침공 당해 거의 전멸하기 직전의 상황에서 톰형이 무슨일인지 장교에서 신분강등이 되어 전투지휘부로 끌러 옵니다. 이후 전쟁에 참여해서 외계인의 분대장격인 알파를 죽이고 그 피를 받으면서 죽으면 하루전으로 가는 능력을 가지게 되는게 이야기의 시작입니다.
처음 도입부는 약간 지겹게 느껴질 수 있습니다. 그는 계속 억울함을 주장하고 전투에 출전하고 죽고 다시 깨어나고의 반복입니다. 그 사이 톰은 무기의 사용법과 전투방법과 미래의 일어날 일을 외우고 자기 부대원에게 전투방법을 가르치며 조금씩 발전을 합니다. 그는 전쟁에 승리하기 위한 강화학습을 진행하고 있는것입니다. 그리고 그로인해 전쟁의 양상은 바뀌게 됩니다.
우리가 하고자 하는 봐도 바로 이것입니다. 우리는 쉽게 주식이나 코인의 거래데이타를 받을 수 있습니다. 그 데이터를 이용하여 수천번의 시뮬레이션을 실시해서 최고의 성적을 내는 시나리오를 얻고 이것을 CNN에 하이퍼 파라메트로 학습하여 이것을 이용하여 실전의 행동과 예상 reward 를 얻는 방식으로 진화할 수 있습니다.
CNN은 머쉰런닝 분야에서 가장 발전한 형태일 것입니다. 처음 시작은 팩스로 전송된 손글씨를 인식하여 데이터화 하는것이었습니다. 그 다음은 개와 고양이 사진을 보고 개와 고양이를 구분하는 논문이 발표됩니다. 그 후 Open AI라는 회사는 DQN이라는 인공신경망을 개발하고 아케이드 게임을 인간보다 잘하는 인공지능을 개발합니다. 이후 레트로 짐 이라는 인공지능 학습환경을 개발하여 일반에게 오픈했습니다.
우리는 그 방법들 중 한가지를 사용하여 DQN을 학습하여 그 DQN이 얼마나 사람보다 주식이나 코인 트레이딩을 더 잘하는지 아님 더 잘할때까지 계속 학습하는 방법을 의논할 것입니다. 저의 글을 보시고 다른 의견이 있으시면 답글 부탁드립니다.
어느 가을이 끝나가는 저녁이었습니다 . 건물과 건물 사이 조금한 뜸으로 아주 어려보이는 냥이 한마리를 정직씨는 보고 말았습니다. 분명 겨울이라고는 말할 수 없는 날짜지만 저녁은 꽤 쌀쌀했습니다. 정직씨는 남의 일에 잘 나서지는 않는 타입이라 지나치려는데 고양이의 오른쪽 눈이 없다는 것을 보고 말았습니다. 가슴 속에는 여러 명의 정직씨가 서로 싸우고 있었습니다. 괜히 귀찮은 일에 휘말리는게 아닐까 걱정도 잠시뿐 정직씨는 냥이를 불렀고 냥이는 사람을 경계하는 눈치지만 천천히 걸어오고 있었습니다. 그때였습니다. 옆 오피스텔의 경비 아저씨가 정직씨를 말렸습니다. "길 고양이에게 먹이를 주시면 안됩니다." 그가 가르키는 곳에는 A4로 출력된 고양이에게 먹이를 주지말라는 경고문과 먹이로 인한 피해를 차근차근 설명하고 있었습니다. 갑자기 정직씨는 화가 났지만 경비 아저씨에게는 화를 낼 수는 없는 일이었습니다. 그 글의 주체가 경비 아저씨가 아니라는 건 길가는 초딩도 알 정도의 상식아닌가? "걱정마세요. 아저씨" 정직씨가 뱉은 말에 아저씨는 안심을 하고 고개를 반대편으로 돌렸지만 불현듯 뭔가 안좋은 것을 본 사람처럼 고개를 정직씨쪽으로 돌릴 수 밖에 없었습니다. 정직씨는 큰 바바리 코드 속으로 냥이를 숙 집어 넣었습니다. 경비 아저씨가 큰 소리로 한마디를 보태었습니다. "그러다 사모님한테 혼납니다. 길거리 동물 집으로 데려가는거 아닙니다" 정직씨가 퉁하게 한마디 했습니다. "저 아직 총각입니다. " '끝에 말은 괜히 했나' 혼자 생각을 하는데 괜실히 얼굴이 붉어졌습니다. 속으로 "흥"하고 아주 크게 말을 합니다. 그리고는 경비 아저씨와는 한참을 멀어지고 나서 바바리 코트 안을 보면서 냥이에게 "우리집으로 가자. 맛있는거 줄게" 정직씨는 아주 좋은 아파트에 삽니다. 전세도 월세도 아닌 자가입니다. 왜 이런 큰집을 사게 되냐면 사연이 깁니다. 정직씨는 사실 좋아하던 사람이 있었습니다. 결혼을 결심하고 이제껏 열심히 모은 돈으로 들꺽 아파트 부터 계약을 했더랍니다. 잔금까지 치러고 나니 진짜 자기집이라는게 믿기지 않았습니다. 정직씨는 사랑하는 그녀에게 할 프로포즈 계획을 세우고 몇일 밤을 끽끽 웃어면서 잠을 잤습니다. 정직씨가 다니는 노무사 사무실은 아주 실적이 좋았습니다. 지금도 그렇습니다. 일한 만큼 돈을 벌어서 한푼도 안쓰고 꼬박꼬박 모아 쾌 큰돈을 모았습니다. 자기와 가족이 될 그 아가씨만 생각하면서. 그 아가씨는 같은 회사에 근무하는 회계업무를 보는 아가씨였습니다. 처음 보았을 때는 정말 천사를 보는 줄 알았습니다. 첫 눈에 반한다는게 이런걸까요? 처음에는 농담을 하듯이 사무실 근처 꽤 비싼 레스토랑에서 저녁식사할 생각있냐고 물었고 아가씨는 아무 고민없이 흔쾌히 약속을 잡았습니다. 내가 지금 꿈을 꾸는건가? 정직씨는 생각을 했지만 티를 낼 수는 없었습니다. 옆자리의 여자 과장님이 있었기에 정직씨는 뭔가를 들키지 않으려는 사람처럼 그 과장님에게도 같이 가자고 했고 그 과장님은 웃으면 거절을 했습니다. "난 남의 청춘사업의 방해꾼이 되는건 사절이 올시다." 그 과장님의 말에도 그 아가씨는 아무런 댓구도 없이 그저 웃기만 했었습니다. 그렇게 만남은 은밀하게 계속 됐습니다. 집을 쌌던 때는 아마도 그때 쯤이었을 겁니다. 결심한 프로포즈를 할려고 준비를 하는 쯤에 갑자기 그 아가씨가 결근을 한것 같았습니다. 정직씨와 그 아가씨는 같은 사무실은 아니라 한참 있다가 그 사실을 알고 그 여자 과장님에게 물어 보러 갔었습니다. "현정씨는 그제 그만 뒀는데 몰랐어요" 순간 머리를 크게 한 방 맞은 것처럼 정신이 없었지만 아무에게도 안 들키고 이 사태를 넘기기 위해서 아무일도 없었던 것처럼 일에만 집중을 했습니다. 아무도 두 사람 사이에 무슨 일이 있었는지는 모릅니다. 정직씨만 아는 비밀이었습니다. 회계팀에는 회사의 막내가 들어 왔습니다. 현정씨가 나간 빈자리를 채우기 위해서지만 고등학교를 갓 졸업한 아이라니 정직씨는 혼자 생각했습니다. 정직씨에게는 그 일로 충격이 상당했습니다. '혼자 북칙고 장구치고 잘 했다 박정직 이 바보 같은 놈' 혼자 생각하며 회계팀 사무실을 돌아 자기 자리로 가고 있는데 조그만 아이가 조그만 손으로 10리터가 넘어 보이는 생수통을 들어 올리고 있었습니다. 정직씨는 한 다름에 달려가서는 소녀에게 물통을 가로채고는 한 마디를 했습니다. "이 사무실에는 생수통 갈 사람도 없는거야?" 정직씨는 갑자기 화가 났습니다.소녀는 부끄러운 얼굴로 빨리 제자리로 가버렸습니다. '마지막 말은 하지말았어야 했는데' 이미 뱉은 말은 주워 담을 수 없는 일이죠. 그냥 자신의 선행으로 끝내면 될 일을 온 사무실에 광고라도 한 것처럼 소녀의 얼굴은 찾을 수 없는 곳으로 꼭꼭 숨어 버렸습니다. 한참 후 잠시 자리를 비운 사이 노란 포스트잇과 빨간 딸기 우유가 있었습니다. 소녀에게 별일 아니라고 말하고 싶었지만 정직씨의 성격으로는 그런 말을 쉽게 할 수 없는 일이었습니다. 그렇게 몇 달이 지난 쯤 하루였습니다. 그 때의 그녀가 떠날 때 처럼 회계팀의 그 자리가 비워있었습니다. 아무런 사심이 없는 정직씨는 자신만만하게 물어 볼 수 있었습니다. "그 막내는 오늘 안나오나요?" 그때처럼 그 옆자리는 늘 그럿듯 그 여자 과장님이었습니다. "응 아파서 휴가냈어" 정직씨는 아무일도 없다는 듯 "그래요"라고 짧게 말하고 그 여자 과장님과 이런 저런 이야기를 나누고는 자리로 돌아갔습니다. 근데 그 다음 날도 막내는 출근을 하지 않았습니다. 그 다음 날도 마찬가지였죠. 정직씨는 아무일도 아니라는 투로 그 소녀의 주소를 물었습니다. 그 여자 과장님도 아무일도 아닌것 처럼 주소를 주면서 안그래도 연락이 안돼서 궁금한데 정직씨가 한번 가보라면 주소를 주었습니다. 주소는 정직씨가 새로 이사한 집 바로 근처였습니다. 정말 처음 알았습니다. 이렇게 가까운 곳에 막내가 사는 줄은. 왜 이때까지 버스에서도 한번도 마주치지 않았나 궁금했습니다. 그날은 조금 일찍 일을 마치고 막내집을 찾아 갔습니다. 정직씨는 그래도 유명한 대학의 법대를 나온 사람이라 혹시 개인정보보호법 위반에 해당 하는건 아닌지 별 쓸때 없는 생각을 하고 있었습니다. 그 소녀의 집은 모퉁이만 돌면 바로 그기 였습니다. 정직씨의 동네는 몇억이 넘는 아파트촌과 빌라촌이 같이 있는 동네였습니다. 빌라가 있는 동네는 지금 당장이라도 재개발을 한다고 해도 이상하지 않을 정도 였습니다. 주소는 딱 봐도 다세대 주택이었습니다. "계세요" 정직씨가 사람을 불러도 아무도 없는 것처럼 조용했습니다. 대문쪽으로 가서 우편물을 보았습니다. 채고장이 꽤 쌓여있는 주소에는 우체부 아저씨의 글씨로 메모가 적혀 있었습니다. 나무 밑집 이라는 메모로 보아 정원에 있는 나무로 좁은 코너를 돌면 있는 집인것 처럼 보였습니다. 그 쪽으로 걸어가는데 안에서 누군가 나왔습니다. 막내였습니다. 얼굴 한쪽은 커다란 멍이 있고 눈은 충격에 파열된거처럼 충혈되어 있었습니다. 힘겹게 인사하는 막내의 손을 잡고 근처의 큰 병원 응급실로 갔습니다. 처음엔 저항하던 손이 힘없이 따라옵니다.병원 응급실에 치료를 받으면서 이곳 저곳을 검사했습니다. 잠시 후 의사로 보이는 젊은 사람이 왔습니다."보호자신가요?" "아니요 그냥 직장 동료입니다. 몇 일째 결근 중이라. .." 정직씨는 말을 마치지 못했습니다. 젊은 의사는 갈비뼈가 몇 군데 뿌러져 병원에 몇일 입원해야 할것 같다는 것과 이런 폭력 사건은 경찰에 신고를 해야 한다는 말을 했습니다. 막내는 경찰에 신고는 하지 말아 달라고 의사에게 사정 사정을 했습니다. 저녁이 한참 지난 시간에 정직씨가 남긴 메모를 보고 누군가 왔습니다. 술 냄새는 십미터 밖에서도 맡을 수 있었고 이 폭력의 주체도 누군지 정직씨는 알 수 있었습니다. 그때 마침 간호사가 정직씨에게 병원 병실이 났다며 알려 주었고 소녀는 간호사들에 의해 병실로 옮겨졌습니다. 자기 자신은 오지랖은 절대 없다고 자신하던 정직씨였지만 그가 틀렸습니다. 완전 오지랖 덩어리 였습니다. 그녀의 아버지는 병원에서도 난동을 부릴 기세였지만 거구인 정직씨를 당할 수는 없었습니다. 이런 인간들은 너무 뻔하다고 정직씨는 생각했습니다. 약한 사람에게 강하지만 강한 사람에게 한마디도 못한다는 것을... 그녀의 아버지는 뒷걸음 치면 점점 멀어졌습니다. 병원비는 정직씩가 계산했습니다. 아까 그집에서 본 채고장 내용으로 봐도 막내에게 돈이 있을리는 만무했습니다. 바로 회사대표 노무사님께 전화를 해서 사정을 이야기 했습니다. 노무사님은 정직씨의 까마득한 학교 선배님이기도 했지만 사람 좋기로 소문난 분이기도 했습니다. 치료가 끝날 때까지는 휴가로 할거니 신경쓰지 말라는 말은 너무도 당연히 나왔습니다. 회사일 마치면 정직씨는 바로 병원으로 향해서 막내를 간호했습니다. 정직씨 또한 사람 좋기로는 대표님에게 지지 않는 사람입니다. 막내의 모든 병원비를 부담했으며 막내는 뿌러진 갈비 사이로 장기가 손상돼 꽤 많은 날을 병원에 있었습니다. 병원에 있는 동안에도 막내는 정직씨에게 한마디도 하지 않았습니다 그녀의 아버지는 그 이후로 한번도 병원을 찾지는 않았습니다. 퇴원하는 날은 정직씨가 휴가까지 내서 막내를 집으로 데려주고 집 청소도 미리 해두었습니다. 그러는 동안에도 그녀의 아버지는 나타나지 않았습니다. 막내에게 내일은 꼭 출근해라라고 말을 하고 다른 영웅들이 그렇듯 아무 말도 없이 그 자리를 떠났습니다. 그러고 그 다음날... 그 소녀는 나타나지 않았습니다. 다시 그집을 찾았을 때는 주인 어른이 다른 세입자를 받고 있습니다. 주인 어른은 그렇게 나쁜 분은 아닌었던가 봅니다. 그 오랜 세월을 월세도 받지 않고 막내 네를 살게 해주었나 봅니다. 그 후로 쪽히 15년은 흐른 것 같습니다. 그 때 곧 결혼 할 수도 있다는 착각에 빠져 혼자 살기엔 너무 넓은 이 집에 아직도 혼자 살고 있습니다. 그 후에도 몇 명의 여자를 만나기는 했지만 이상하게 정직씨가 먼저 관계를 정리하게 되었습니다. 아무도 모르는 정직씨만의 트라우마가 있는 듯 했습니다. 넓은 집에 냥이를 내려 두고 참치캔 하나를 따서 시리얼 그릇에 넣고는 냥이에게 주었습니다. 게눈 깜추기라는게 이런걸 보고 하는 말 일겁니다. 내일은 토요일입니다. 잠을 자고 친구가 하는 동물병원을 가기로 생각을 했습니다. 밤새 냥이는 정직씨의 옆을 한번도 벗어나지 않고 계속 옆에만 있었습니다. 서로가 처음 느끼는 그런 온도였습니다. 뭔가 전해지는 따뜻함이 둘을 깊은 잠으로 인도해 주었습니다 정직씨는 오랜만 꿀잠에서 깨서는 어제처럼 참치캔을 딴 다음 냥이에게 주고 인터넷으로 고양이 키우는 법에 대한 검색을 하고 샤워를 했습니다. 냥이는 욕실 문앞에 한 발짝도 안 떠나고 있어서 정직씨는 문을 열어 두고 샤워를 마쳤습니다. 차를 타고 친구의 동물병원에서 냥이의 검사를 했습니다. 어린 녀석이 누구한테 맞은건지 갈비 뼈가 뿌러져 아문 흔적이 있었습니다. 친구는 농담으로 "길 고양이 함부로 집에 들이는 거 아니다. 이놈들 식구를 늘리는 재주가 있거든 암튼 주의하도록" 집으로 돌아온 정직씨는 냥이랑 같이 동네를 산책할 생각입니다. 겨울이 막 오고 있었지만 가벼운 옷 차림으로 냥이를 안고 한손에는 농구공을 들었습니다. 넓은 공터가 있는 놀이터 맞은편은 옛날 막내가 살던 집이 있습니다. 농구를 조금 했지만 냥이를 데리고 농구를 한다는 것은 불가능했습니다. 의자에 잠시 앉아 바람을 새고 있었습니다. 그 새 토요일 오후는 끝나고 어뚝한 저녁이 찾아 왔습니다. 그때였습니다. 냥이가 갑자기 달리기 시작했습니다. 정직씨도 냥이를 따라 달렸습니다. 저기 멀리서 다투는 소리가 나는 것 같았습니다. 가까이 가서 보니 다툼이 아닌 일방적 폭력이었습니다. 아이 셋이 울고 있었고 아이들의 엄마로 보이는 사람이 남편으로 부터 맞고 있었습니다. 정직씨의 오지랖이 다시 깨워나는 순간이었습니다. 남자를 막아서며 남자의 손을 힘으로 억세게 잡았습니다. 혼자 생각 했습니다 이런 류는 내가 잘 알지 약한자에게는 강하고 강한자에는 한없이 약한 버러지들... 딱 봐도 거구인 정직씨를 힘으로 이길 사람은 그리 많지는 않았습니다. 남자의 손을 놓고 애들에게로 가서 괜찮은지 물었습니다.그리고 엄마에게로 가는데 순간 숨이 멎는것 같았습니다. 막내였습니다. 아니 더 이상은 막내가 아닌 그 옛날의 그 소녀였습니다. 이름도 기억나지 않았습니다. 기억에서 지워버린 아니 애쓰지 않아도 잊혀질거라 생각한 사람입니다. 정신이 멍해서 가만히만 서 있어야 했습니다. 그 때였습니다. 뒤에서 누군가 몽둥이로 내려 쳤습니다. 애들의 아버지 였습니다. 순간 화가 머리 끝까지 오른 정직씨는 그 남자를 주먹으로 패기 시작했습니다. 생에 첫 폭력이었습니다. 그녀가 말리는 소리에 정신을 차리고 일어나서 그녀를 바라봤습니다. 15년전 그때처럼 그녀의 맞은 상처를 보고 연신 괜찮는지 물어 보고 있었습니다. 그때 그녀의 남편은 어느새 집에서 칼을 가지고 와서 정직씨를 질렀습니다. 살짝 베이기는 했지만 칼을 들고 있는 상대는 계속 위협을 하고 있었습니다. 갑잡기 냥이가 그 사람의 얼굴을 할퀴고 날아갔습니다. 이때 정신을 차린 그녀는 아까 그녀의 남편이 들고 있던 뭉둥이로 있는 힘것 내리쳤습니다. 남편은 숨을 쉬지 않는 것 같았습니다. 아이들과 그녀의 손을 잡고 집으로 달렸습니다. 15년전 그날이 생각 낳습니다. 그날은 그렇게 저항하던 손이 오늘은 그를 따라 달리고 있었습니다. 집에 도착해서 아이들과 그녀를 두고 그는 다시 그곳으로 달렸습니다 냥이를 두고 온 것이었습니다. 모든 일이 하루 사이에 일어난 일이라 또 냥이를 잃어버리면 그 녀석은 하루만에 주인에게 버림 받게 되는 거라 생각했습니다. 그때였습니다. 경찰차 소리에 정신을 차리고는 걸음을 멈추었습니다. 구급차도 그곳에 와 있었지만 다행히도 그 남자는 죽지는 않았습니다. 정직씨는 경찰에게로 걸어갔습니다. 저 사람을 때린 사람이 본인임을 밝히고 경찰차에 올라탔습니다. 그때 냥이가 보였습니다. 경찰관에게 기르던 고양이라고 말하고 함께 갈 수 있게 해달라고 애원했습니다. 경찰서 유치장에는 고양이와 40대 말의 아저씨가 있었습니다. 경찰관은 정직씨에게 쌍방 폭행에 상대는 칼을 들고 있어 서로 합의하면 나갈 수 있다고 보호자는 없냐고 했습니다. 그때 그녀가 경찰서 입구로 천천히 걸어 왔습니다. 경찰에게 그날의 일을 상세히 이야기하고 남편을 가정폭력으로 신고를 했습니다. 경찰은 정직씨를 풀어주고 그 둘과 그의 고양이는 집으로 천천히 걸어 갔습니다. 집에 도착할 때까지도 둘은 아무말도 하지 않았습니다. 그동안 어떻게 살았는지 그런 우스운 얘기를 나눌 그런 사이도 사실 둘은 아니었으니까요. 집에 오자 그녀에게 갈곳이 없으면 여기 있어도 좋다고 했고 아이들은 벌써 신이 났습니다. 막내 아이가 이 고양이는 왜 눈이 없냐고 물었습니다. 대답을 해주려했지만 애초에 대답에는 관심이 없었나 봅니다. 다음날 경찰이 찾아 왔습니다. 남편은 병원에서 바로 입건이 됐지만 가정폭력은 반의사불벌죄라 불원서를 쓰시면 남편도 풀려날 수 있다면 같이 살던 남편인데 감옥에 가는건 좀 그렇지 않냐고 했습니다. 그녀가 앞으로 한발짝 나서려 할때 정직씨는 그녀의 손을 잡았습니다. 어제의 그녀처럼 15년전의 그녀와는 다르게 정직씨의 말을 따랐습니다. 그녀는 불원서를 쓰지 않았습니다. 정직씨가 소개시켜준 변호사를 통해서 이혼 소송도 진행했습니다. 그 후에도 시간이 많이 흘렀지만 그녀는 그집을 떠나지 않았습니다. 어떤 하루였습니다. 정직씨는 직장에서 돌아오는 그녀를 차에 태우고 어디론가 갔습니다. 그때의 그녀처럼 아무말없이 정직씨를 따랐습니다. 그리고 그들은 한강이 보이는 곳에 도착했습니다. 그기에는 정직씨의 부모님이 뭍여 있는 묘지가 있었습니다. 그녀에게 말했습니다. "저희 아버지 어머니신데 같이 인사올려도 될까요?" 그녀는 아무 말도 하지않고 있었지만 입가엔 잔잔한 미소가 보였죠. "아버지 어머니 저랑 결혼할 사람입니다. 너무 늦게 데려와서 죄송합니다 그렇치만 우리 둘은 절대로 헤어지지 않을 겁니다." 그 다음날은 토요일입니다. 아이 셋과 그녀 그리고 냥이를 데리고 친구의 동물병원으로 들어갔습니다. "식구가 늘 거라고 말했지"라고 장난스럽게 친구가 얘기했습니다. 그녀가 정말 오랜만에 말을 했습니다. 자기가 고등학교때 학교에서 몰래 키운 고양이가 있었다고 말입니다. 그 고양이도 오른쪽 눈을 잃었는데 지금의 냥이를 보면 그때가 생각난다고 했습니다. 학교의 불량배들에게 발로 배를 차여서 크게 다친 일이 있었는데 계속 그곳에서 그 고양이를 키우면 그 불량배들에 죽임을 당할 것 같아 멀리 보냈다고 했습니다. 하지만 냥이는 한살에서 두살 정도고 그녀의 고등학교 시절이면 약 20년이 가까운 시간인데 같은 냥이 일 수는 없습니다. 집으로 돌아와 온 가족이 모였습니다. 아이들에게 엄마랑 결혼 할거라는 이야기를 했습니다. 아이들은 벌써 부터 신이 났습니다. 막내가 정직씨에게 물었습니다. "아저씨 이제 아빠라고 불러도 되요" 대답을 하려고 했지만 대답에는 관심이 애초부터 없었나 봅니다. 막내는 냥이와 함께 다른 방으로 가버렸습니다. 온 가족이 다들 뭐가 좋은 지 환하게 웃고 있었습니다.
scikit-learn을 제가 처음 접한 때는 아직 정식버전을 내놓지 않은 0.x 버전이었습니다. 또한 서점에 나와 있는 책이나 블로그의 내용들도 그러한 이유로 0.x버전의 책이었습니다. 현시점에 scikit-learn은 1.x 버전을 내놓은 상태입니다. 먼저 scikit-learn은 tensflow와 자신의 영역을 분명히 하고 있으며 가는 방향도 다르다고 선언을 했습니다. tensflow가 고성능의 고용량의 데이터에 대한 데이터 분석 및 학습을 목표로 한다면 tensflow를 사용할 수 없는 또는 시스템이 지원하지 않는 영역에서의 분석 및 학습이 scikit-learn의 영역임을 분명히 했습니다. 제가 개발하려는 환경 또한 위의 환경입니다. 저의 개발 및 운영 시스템으로 오라클 클라우드에서 제공받고 있는 평생 무료 서버를 사용하고 있습니다. 그 상황에서 데이터를 얻어서 TA-Lib로 매매데이터를 분석하고 매수 목표나 매도 목표를 찾는 시스템을 운영하고 있습니다. 따라서 당연히 GPU는 사용할 수 없으며 tensflow나 keras의 고급 머쉰 러닝은 사용할 수 없습니다. 하지만 이러한 제약으로 인하여 scikit-learn을 사용하려는 것은 아닙니다. scikit-learn의 구조는 매우 단순한 구조를 가집니다. 데이터의 획득, 학습 데이터와 테스트 데이터의 분류, 학습(fit), 학습 데이터 평가(score), 예측(predict)의 구조가 전부이며 각각의 구조가 scikit-learn의 함수들 각 하나로 이루어져 있습니다. 제가 초기에 scikit-learn을 배우고 적용하는 것이 힘들었던 이유가 바로 위의 내용이기도 합니다. 머쉰 러닝이 간단해도 이렇게 간단할 수 있을까? 하는 의심이 학습을 방해한 이유 중 하나였으며 너무 간단하다 보니 사실 책을 쓰시는 분이나 블로그들의 글도 많지 않을뿐더러 서점의 책도 별로 없는 상태였습니다. 그리고 머쉰 러닝 하면 그 당시 대부분이 tensflow에 대하여만 생각하는 분위기라 scikit-learn을 아는 사람도 별로 없었죠.
2. 목표를 분명하게
제가 하려는 건 분명합니다. 기존에 수집 및 TA분석중인 데이터를 scikit-learn로 재분석하여 가장 데이터에 맞는 scikit-learn의 분석모델을 찾는 것이며 데이터를 최적화하는 것입니다. 위의 왜 scikit-learn인가에서도 아셨겠지만 scikit-learn을 배우는 것은 어렵지 않습니다. 공식 사이트의 연습 문제만 풀어도 내용을 알 수 있지만 제가 중요하고 어렵다고 본 것은 scikit-learn이 아닙니다. 기존의 데이터를 scikit-learn의 데이터로 변환한 다음 모델의 정확도를 지속적으로 높일 수 있으면서 성능이 뛰어나며 실제 매매 엔진을 방해하지 않는 것입니다. 보통 매매 엔진은 1분 데이터를 수집하는 경우 데이터 수집과 매수, 보유, 매도를 결정하고 실행하는 데까지 모두 1분 안에 끝내야 합니다. 이 1분이 초과된다면 그 다음은 3분 데이터를 사용한 매매 엔진을 다시 개발해야겠죠. 각각의 분석의 정확성에 따라 기존의 매매전략을 다시 만들어야 할 수도 있으며 완전히 새로운 방식을 고민해야 할 수도 있을 것입니다.
3. scikit-learn의 학습이란?
scikit-learn의 학습에 대하여 생각하기전에 먼저 일반적인 딮런닝을 생각해 봐야겠네요. y = a1 * x1 + a2 * x2 + a3 * x3 + ... + an * xn + b 위의 식의 y는 우리가 딮런닝 예측으로 구하려고 하는 값입니다. 딮런닝의 예측에는 분류(Classify)와 회귀(Regress)가 있습니다. 우리가 해결해야 하는 문제가 분류인지 회귀인지를 스스로 판단하고 알아야 합니다. 분류는 붓꼿의 품종을 예측하는 것처럼 집합의 범위가 적으며 정해져 있는 경우일 겁니다. 각 투수별 구종을 학습하여 야구 선수가 다음번에 어떤 공을 떤질지를 딮런닝으로 학습한다면 이런 경우는 범위는 조금 많지만 분류에 해당한다고 할 수 있습니다. 회귀는 무엇일까요? 주가를 예측하는 딮런닝 모델이 있다고 한다면 주가와 주변의 환경변수를 이용하여 주가를 예측할 수 있을 것입니다. 주가를 예측하기 전에 하나의 곡선(또는 다차원 평면)을 그릴 것입니다. 그리고 그 곡선에 학습에 사용한 환경변수를 대입하여 하나의 값을 구할 수 있을 것입니다. 위의 곡선을 구하는 것을 회귀라 하며 주가의 예측은 회귀에 의해서 그려진 곡선에 각각의 좌표를 이루는 값을 대입한 결과가 예측한 주가가 될 것입니다. 그런데 이 곡선은 우리가 수학 시간에 배웠던 2차원 직선이나 3차원의 곡선이 아닙니다. 환경변수의 수가 n이라고 하면 n차식의 곡선인 거죠 그리고 이 n차식에 들어가는 변수가 우리가 학습에 이용한 환경변수( ※ DB 테이블로 치면 컬럼에 해당할 것입니다.)입니다. 위의 식이 바로 이러한 딮런닝을 표현한 식입니다. 아마도 이 글을 읽는 순간 갑자기 어려워하시는 분들이 있을 수 있으나 우리가 해야 하는 일은 우리가 구하려는 값이 분류에 있는지 회귀에 있는지 잠깐 생각하는 게 전부입니다. 주가나 필라델피아 주택 가격이나 금의 시세나 또는 달러의 시세를 예측하는 프로그램이 있다면 이 것은 회귀일 가능성이 높습니다. 그렇다면 이런 문제는 어떨까요? 근 미래의 주가가 오를지 내릴지를 맞추는 딮런닝 프로그램이 있다면 이것은 분류일까요? 회귀일까요? 당신은 이 문제를 어떻게 접근하실 건가요?
4. 데이터 수집
한국투자신탁의 뱅키스API나 upbit API를 이용하여 1분 데이터를 수집하는 프로그램을 작성할 수 있을 것입니다. 사실 꼭 1분일 필요는 없습니다. 30분 데이터로도 훌륭한 데이터 수집 및 분석 프로그램을 만들 수 있습니다. 사실 시간은 의미 없는 눈속임일 수 있습니다. 저는 이렇게 가져온 데이터를 TA-lib(https://mrjbq7.github.io/ta-lib/install.html)를 사용하여 분석후 이용하고 있습니다. 하지만 한 가지 문제를 가지고 있습니다. TA(기술적 분석)은 사실문제를 가지고 있습니다. 그것은 바로 분석된 데이터의 후행성입니다. 예를 들면 60분 ma(이동평균선)을 보면 7~10분 정도 먼저 주가가 올라가고 나서 이동평균선이 상향으로 움직인다는 것을 알 수 있습니다. 반대로 주가가 빠질 때는 주가가 먼저 빠진 후 이동평균선이 하향으로 움직이는 것을 볼 수 있습니다. 이것은 TA 데이터가 거의 대부분이 과거 데이터의 평균값을 이용하고 있으며 미래의 예측이 아니기 때문에 발생하는 문제입니다. 주가 차트의 가장 저점은 사실 그 지점에서 반등한다면 최고의 이익을 선사할지도 모르지만 그 지점마저 무너진다면 우리에게 지옥의 맛을 보여줄 자리 일 수도 있습니다. 더는 내려갈 곳이 없다고 생각하는 것은 인간의 어리석음일 수 있습니다. 가치 투자자들은 자신의 판단에 맡겨 이 정도 값이면 더 내려도 괜찮아라고 생각하겠지만 매매 프로그램 자체가 이미 가치 투자가 아니므로 이런 매매 프로그램에게 그러한 자리는 아주 치명적일 수 있습니다. 모든 상품 및 현물은 성장기 확장기 감쇠기 쇠퇴 기를 반복하지만 거짓된 상품은 확장기에서도 갑자기 가치가 0에 수렴할 수도 있습니다. 그런 경우까지 매매 프로그램이 감지하는 경지까지 아직 딮런닝 프로그램들이 발전하지 않았습니다. 딮런닝 중의 한 부야에는 제한적 학습이라는 분야가 있습니다. 제한적 학습은 많은 경험과 함께 그런 제한적 학습을 어떻게 적용할 것인지를 알아야 될 뿐 아니라 scikit-learn의 학습으로는 불가능할 수 있습니다. scikit-learn은 0.x 버전 때보다는 지금은 엄청나게 많이 발전했지만 scikit-learn은 한 가지 단점이 있습니다. 다른 딮런닝 모듈보다는 확실히 사용하기 쉽지만 다른 일부 엔진처럼 각각의 모듈을 customize 하기에는 제한적이라고 할 수 있습니다. 그런 customize가 가능하려면 여러분 들은 모든 분류엔진과 회귀 엔진을 직접 구현할 수 있을 정도의 실력이 필요하지 않을까요?
async def read_all(sqlcon) -> pd.DataFrame:
try:
cursor = await sqlcon.cursor(aiomysql.cursors.DictCursor)
str_query = """select
`time`, start, close, high, low, volume, sma1200, sma1200_degrees, wma1200, wma1200_degrees
from %s""" % table_name
await cursor.execute(str_query)
data = await cursor.fetchall()
datadf = pd.DataFrame(data)
return datadf
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
logger.error("read from db exception! %s ` : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
finally:
await cursor.close()
async def trade_proc():
pool = await aiomysql.create_pool(host="호스트ip 또는 이름", user="root", password='pass', db='dbname')
async with pool.acquire() as sqlcon:
df = await read_all(sqlcon)
sqlcon.close()
df['futher'] = df.close.shift(-5)
df['futher_mid'] = df.close.shift(-5) - df.close
df['predict'] = (df.close.shift(-5) - df.close).apply(lambda x: (-1 if x < 0 else (0 if x == 0 else 1)))
df = df.dropna()
await regressor(df) #실제 학습 함수
async def regressor(df):
X_data = df.drop(['futher', 'futher_mid', 'predict'], axis=1)
X_new = df.drop(['futher', 'futher_mid', 'predict'], axis=1).tail(5).head(1)
X_clct = df.tail(5).head(1)
y_data = df['futher']
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, random_state=0)
mlp = MLPRegressor(solver='lbfgs', max_iter=500, random_state=0)
mlp.fit(X_train, y_train) # 학습
logger.info("MLP 훈련 세트의 정확도: {:.2f}".format(mlp.score(X_train, y_train)))
logger.info("MLP 테스트 세트의 정확도: {:.2f}".format(mlp.score(X_test, y_test)))
joblib.dump(mlp, 'mlp.jdmp')
if __name__ == '__main__':
asyncio.run(trade_proc())
기존 DB의 데이터로만은 scikit-learn의 학습이 불가능할 수 있습니다. 학습에는 x1...xn에 들어가는 기본 필드도 필요하지만 답에 해당하는 y_data도 필요합니다. 이런 데이터는 pandas를 이용하면 쉽게 구할 수 있습니다. pandas는 기존의 관계형 DB의 속성과 함께 nosql의 속성 및 큐빅 DB에서 볼 수 있는 DB의 세로(칼럼) 간 연산도 가능합니다. pandas의 이러한 기능은 scikit-learn의 학습 데이터를 아주 쉽게 만들 수 있습니다. 위의 예제 소스는 기존의 DB를 이용하여 scikit-learn 학습 데이트를 만드는 예제입니다. regressor함수는 회귀 학습을 위한 예제입니다. 현재의 데이터로 미래의 값을 예측하기 위해서 과거의 데이터의 과거 시점 5분 후의 데이터를 이용하여 further와 further의 평균, 그리고 예측값을 만들어 y_data를 만든 다음 X_data에서는 해당 값을 제거하여 학습하는 것을 볼 수 있습니다. 여기서 주의할 점은 scikit-learn의 학습능력은 생각보다 정확하여 예측에 사용된 값을 그대로 넣고 학습을 할 경우 학습률 100%의 데이터를 생성하게 됩니다. 물론 실전능력은 떨어지게 됩니다. 학습 시 해당 예측값까지 이용하여 예측값 공식을 만들기 때문에 해당 필드의 가중치가 최고가 되어 결국은 학습이 의미가 없어지게 됩니다.
5. 지속 가능한 학습이란?
지속 가능한 학습을 위해서는 자료 수집과 학습 및 실전예측 프로그램의 설계가 중요합니다. 자료 수집 및 학습이 배치(BATCH) 작업화 되어야 하고 학습된 모델은 파일로 저장되어 실측 프로그램에서 사용되어야 합니다. 자료 수집 및 학습은 매우 큰 시간이 필요하므로 자료 수집과 학습을 실측 프로그램과 분리하여 운영해야 합니다. 아래 섹션 6에서는 모델을 저장하여 이용하는 방법을 소개하고 있습니다. scikit-learn은 모델을 학습하고 학습된 모델을 파일로 저장하고 저장된 파일 자체를 로딩하여 파이썬의 함수로 사용할 수 있는 모듈을 제공하고 있습니다.
6. 모델의 저장 및 학습모델로 예측하기
scikit-learn은 학습한 모델을 python liberary로 분석하여 파일로 저장하는 기능과 그 파일을 불러와서 예측을 하는 함수를 제공합니다. 많은 양의 데이터를 학습하면 모델의 정확도는 당연히 증가할 겁니다. 하지만 학습에 소요되는 시간은 엄청나게 길어집니다. 만약 매번 학습을 돌리고 그 학습 데이터를 이용하여 예측을 진행한다면 제가 2번 섹션에서 이야기한 1분의 시간은 넘어가 버릴 겁니다. 그렇다면 scikit-learn의 학습은 아무런 소용이 없습니다. 하지만 scikit-learn은 joblib.dump라는 함수를 제공합니다.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import joblib
X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, random_state=0)
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train) #학습
logger.info("KNN 훈련 세트의 정확도: {:.2f}".format(knn.score(X_train, y_train)))
logger.info("KNN 테스트 세트의 정확도: {:.2f}".format(knn.score(X_test, y_test)))
prediction = knn.predict(X_new)
logger.info("KNN 예측 결과:%d", prediction)
joblib.dump(knn, 'knn.jdmp') #모델 저장
위의 소스코드가 사실은 scikit-learn의 전부 입니다. tensflow의 keras 보다는 월등히 쉬운 코딩이 가능합니다. 6라인을 보시면 아시겠지만 scikit-learn의 모든 모델은 클래스 화해서 모듈화 되어 있습니다. 위에 이야기한 것처럼 scikit-learn이 문제가 아니라는 것을 여러분은 느끼실 겁니다. scikit-learn의 소스는 5라인부터 끝까지가 전부입니다. 모든 클래스는 분류이면 Classifier가 붙을 것이고 회귀이면 Regressor이 붙을 것입니다.
mlp = MLPRegressor(solver='lbfgs', max_iter=500, random_state=0)
mlp.fit(X_train, y_train) # 학습
logger.info("MLP 훈련 세트의 정확도: {:.2f}".format(mlp.score(X_train, y_train)))
logger.info("MLP 테스트 세트의 정확도: {:.2f}".format(mlp.score(X_test, y_test)))
joblib.dump(mlp, 'mlp.jdmp') #모델 저장
위의 소스는 다층신경망 회귀를 이용하여 학습하고 그 학습된 모델을 모듈화 하여 mlp.jdmp파일로 저장하는 소스입니다. 여기서 중요한 부분은 그냥 단순히 학습된 모델을 파일로 저장하는 것이 아니라는 것이다. 저장된 파일을 로딩하면 바로 파이썬 함수로 사용이 가능합니다. 많은 데이터를 학습하려면 몇분에서 많게는 몇시간의 시간이 필요할 수도 있지만 학습이 끝나면 실제 데이터로 예측을 수행하는데는 그리 길지 않은 시간이면 됩니다.
mlp_from_model = joblib.load('mlp.jdmp') #파일로 저장된 모델을 파이썬 함수로 로딩
prct = mlp_from_model.predict(X_new) #로딩된 모델을 실제 값으로 예측
print("예측값:" + prct) #예측 값은 prct변수에 들어 간다. prct값은 int나 double이 아닌 Dict type입니다
실제 운영되는 실행파일에 위의 내용이 있으면 될 것입니다. 학습에 오랜시간이 걸리겠지만 predict함수가 실행되는 데는 단 몇 초면 끝입니다. 위의 예제는 실제 사용 가능한 다층 신경망 회귀와 근접 이웃 분류의 소스 코드입니다.
7. 글을 마치며
프로그래머가 위의 소스를 보고도 딮러닝 프로그램을 작성하지 못하는 이유는 뭘까요? 사실 위의 소스는 scikit-learn학습을 구현한 소스 전체나 마찬가지 입니다. 차라리 수학, 통계학, 데이터 과학을 전공한 분들은 위의 소스를 보면 바로 scikit-learn 프로그램을 뚝딱 개발하실 수 있을 것입니다. 하지만 이게 다가 아닙니다. 위의 소스가 살아서 움직이려면 기초 데이터의 수집, Database의 연동, 그리고 기초 데이터를 다시 분류하고 스프레드 하는 작업이 필요할 것입니다. scikit-learn프로그램을 운영하려면 적어도 2개 이상의 프로그램이 필요함을 단번에 알 수 있습니다. 하나는 모델의 학습을 하나는 모델을 불러와서 실제 데이터에 적용하는 프로그램이 될 것입니다.
신한은행에서 근무 중이다. 어쩌다 돌고 돌아 햇볕 드는 창가자리에 안게 되었다. 남산이 보인다. 어제 내린 눈이 녹아 창가로 물이 떨어진다. 햇빛에 산이 온통 눈이 부신다. 사실 나는 불가 몇 개월 전 해도 심한 불면증 상태였었었. 겨우 한두 시간을 자면 깨서는 눈이 말똥말똥해진다. 정신과 치료를 받으면서 시간은 네 시간 정도로 늘었지만 상태는 마찬가지다. 지금 이 자리가 좋다. 나를 아침이라고 마구 깨우는 극성스러운 엄마처럼 햇살이 참 반갑다. 세상이 다 아름답다. 아침햇살로 온 세상이 황금빛을 내뿜으며 시끄럽게 소리친다. 난 눈이 부셔 세상을 똑바로 쳐다볼 수도 없다. 건물마다 내뿜는 허연연기는 이 세상이 아직 멈추지 않고 건재하다는 것을 소리치고 있는 것 같다. 온 세상이 아름답다
완다 & 비젼은 마블 페이저4의 첫작품이자 디즈니+로 공개한 마블의 첫 작품이다. 더불어 새로운 어벤져스의 구성원을 하나 하나 만들어 가는 과정이자 코믹스와의 차이에 대한 설명이자 코믹스의 오마주일 것이다. 제목 완다비젼은 중의적인 제목으로 완다가 점령한(?) 웨스트뷰에 대한 완다의 시점이자 완다의 어린시절 트라우마인 소코비아 안에서의 어린시절 미국 시트콤을 보고 두려움을 극복한 과거에 대한 완다의 잠재의식을 표현하는 방송의 제목이다. 감독은 첨부터 갖가지 떡밥을 투척하면서 이 상황이 정상이 아님을 암시하지만 완다는 이상하다는 생각만하고 적극적 대처는 없다. 이 드라마는 총 9회까지 지만 3회를 버텨 내야한다.모든 OTT드라마가 그러하듯 시청자가 되거나 거부되는 것은 처음 첫회 그리고 위기의 순간이 있다. 이 드라마도 그렇다. 처음부터 3회까지는 미국의 TV역사물처럼보이지만 사실은 시트콤의 형태 점점 진화하고 처음 갈색,백색에 가까운 톤에 진한 회색톤에 그리고 칼러TV로 진화하고 내용도 처음은 애니가 섞인 흑백TV에서 최근 시트콤형식으로 점점 진화한다. 그리고 드디어 4화서 이 모든게 현실이면 또한 완다의 환영임이 들어난다. 페이즈4중 그나마 잘 만든 드라마 지만 나중 닥스2를 위한 밑밥으로 사용되고 끝나버린다. 그리고 닥스2 또한 완다비전의 서사가 나오지 않기때문에 완다비젼을 보지않은 관객은 왜저래가 절로 나온다. 케빈 파이기의 작전에 전면 수정이 필요해 보인다. 드라마는 호불호가 완전 갈려 닥스2를 봤지만 드라마를 안본 사람 또한 많게 된다. 그러면서 닥스2는 박스오피스로는 성공하지만 이전 페이즈3처럼 뭔가 다음 이야기가 그렇게 기대되지는 않게 되었다.
오늘은 자동매매 프로그램 구현에서 중요하지만 주제와는 약간 빗겨간 DB 내용중 Upsert(Update or Insert)에 대하여 이야기 하고자 합니다. pandas의 DataFrame은 Nosql적 성격을 가진 아주 휼륭한 Lib입니다. 사실 pandas가 없다면 지금의 자동매매 프로그램의 구현은 힘들다고 해도 이견이 없을 것입니다. 하지만 pandas DataFrame을 사용하다보면 계산이 다 끝나서 이제는 실제 DB로 옮겨야 하는데 기존 제공하는 to_sql은 뭔가 약간은 부족합니다. to_sql함수는 중복이 있으면 insert 실패 처리 하거나 table 전체를 replace하거나 또는 그냥 append하는 것 입니다. 저는 지금은 pandas와 mysql을 사용하고 있지만 초창기는 sqlite3을 사용하였고 mysql로 DB를 변경하면서 문제가 발생했습니다. to_sql의 replace기능이 DB를 삭제하는 과정에 프로그램이 먹통이 되고 이때까지 모아온 소중한 데이터가 다 날아 가는 거죠. sqlite사용중에도 프로그램을 중간에 내릴때 타이밍이 안좋으면 table을 그대로 날려 먹는 경우가 생깁니다. 그래서 현재 인터넷에서는 pandas의 to_sql에 새로운 옵션인 upsert가 화재 입니다. 일부 개발 git에는 upsert가 구현되어 올라와 있지만 pandas의 to_sql을 ctrl + link로 따라 가보면 근본적인 sql lib에 있는 기능을 사용하고 있어 수정하는 것이 대공사라는 것을 금방 알 수 있습니다. 오늘은 제가 구현한 Upsert에 대하여 내용을 공유하고자 합니다.
2. Upsert구현
먼저 아래 소스를 보시죠.
def trade_data_update(df, dbcon, tb_name, if_exists: str='ignore'):
try :
cols = [column for column in list(df.columns)]
str_query = ""
if if_exists == 'fail':
str_query += "INSERT INTO %s (" % tb_name
elif if_exists == 'replace':
str_query += "REPLACE INTO %s (" % tb_name
else:
str_query += "INSERT IGNORE INTO %s (" % tb_name
for col in cols:
str_query += "`" + col + "`,"
str_query = str_query[:-1]
str_query += ")"
rows_val = []
for index in df.index:
rowval = []
for column in df.columns:
rowval.append(df.loc[index, column])
rows_val.append(rowval)
str_query += " values "
for rows in rows_val:
str_query += "("
for row in rows:
if str(type(row)) == "<class 'str'>":
str_query += "'" + str(row) + "',"
elif str(row) == "nan":
str_query += "NULL,"
else:
str_query += str(row) + ","
str_query = str_query[:-1]
str_query += "),"
str_query = str_query[:-1]
cursor = dbcon.cursor()
cnt = cursor.execute(str_query)
# logger.info("apply row cnt:%d", cnt)
cursor.close()
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
logger.error("trade_data_update -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
mysql기준 쿼리 입니다. mysql 에 INSERT에는 총 4가지의 방법이 있습니다. INSERT ON DUPLICATE KEY와 REPLACE INTO, INSERT IGNORE INTO, 그리고 그냥 INSERT입니다. 당연히 그냥 INSERT를 사용하면 INSERT과정에 Dup key가 발견되면 그 부분에서 바로 에러 후 다음으로 넘어 가겠죠. 나머지 3가지는 이렇게 Dup key가 발견되었을때의 예외 처리 방법을 기술한 것 입니다. 저는 보통 회사에서 프로그램할때는 INSERT INTO 보다는 REPLACE INTO를 많이 사용하는 편인데 지금 자동 매매에서는 INSERT IGNORE INTO를 많이 사용하고 있습니다.
다음 회차에서는 이렇게 모인 데이터를 활용하여 실제 training을 공유할까 합니다. 위의 Upsert를 이용하는 이유는 1분 데이터이다 보니 가끔 데이터 유실이 발생합니다. api나 프로그램의 문제가 아니라 upgrade를 위해서 잠시 프로그램을 내려 놓을때 수신하지 못한 데이터가 발생하는 거죠. 1회 수신 데이터를 100개 정도만 받아도 위의 방법을 사용하면 유실 없이 DB에 데이터를 저장할 수 있습니다.
여러분들이 파도를 탄다면 어떤 방식으로 파도를 탈까요? 여러분들은 모험을 좋아하나요? 저는 땅에서 발을 뛰는 행위 자체를 싫어 합니다. 그래도 돈에 대해서는 모험을 즐깁니다. 또 신기하게도 저는 오른손 잡이 지만 돈에 관련된 거의 대부분의 것은 왼손 잡이 입니다. 돈을 세는 것도 나도 모르게 왼손을 사용하고 있었습니다. 심지어는 화투폐도 왼손으로 돌립니다. 제 돈의 뇌는 아마도 오른쪽에 있나 봅니다. 자 여러분은 지금 Bitcoin이라는 파도를 타야 합니다. 어떤 보드를 선택하실 건가요? 저는 초기에는 5분데이터에 MACD로 파도타기를 했지만 성적은 좋지 않았습니다. 여러 파라메트를 변경해 보았지만 결국 MACD의 최대 약점은 가짜 매수, 매도가 발생하여 수익률이 떨어지지만 일정하게 매매가 발생하여 어느 정도 평균 수익을 만들 수는 있었습니다. 문제는 Bithum의 수수료였습니다. Bithum의 경우 0.25%로 매수,매도를 할 경우 0.5%의 수수료가 발생하고 요즘 주식 수수료가 0.015%인 것에 비하면 엄청난 금액입니다. 저 같은 경우 0.05% 수수료라는 말에 50만원짜리 정액 쿠폰을 싸서 거래를 했지만 결국 반 정도밖에 사용하지 못해서 수수료 할인을 거의 이용하지 못했습니다. 거래 금액 10억까지 무료였지만 거래금액이 5억이 되는데는 몇일이 걸리지 않았습니다. 지금은 upbit로도 프로그램을 돌리는데 upbit의 경우 모든 KRW시장거래에 0.05%의 수수료를 적용하고 있고 정액쿠폰 같은 것은 판매하지도 않기 때문에 훨씬 편리한것 같더군요. 결국 매매 후 금액이 수수료를 초과하지 않으면 이 게임은 실패입니다. 그래서 제가 생각한 방법은 종가최대최소값 밴딩 방법입니다.
2. 종가최대최소값 밴딩 이란?
pandas의 rolling함수를 이용하면 특정 구간에 min값 max값 평균값을 구할 수 있습니다.
위의 내용처럼하면 해당 구간의 최고가와 최소가를 구할 수 있습니다. max값을 예로 들어보면 해당 구간의 max값은 한번 최고점을 찍으면 f(n+1)=f(n)의 공식이 성립되면서 min값과 같이 일종의 밴드(쌍으로 같이 움직이는 그래프)를 만듭니다. 두 곡선의 절대 만나지 않습니다. 비트코인이 망하지만 안는다면 말이죠. 비트코인처럼 변이가 심한 자산의 경우 절대 수익을 보장하는 매수,매도 공식이 가능하지만 가끔 박스권을 형성하는 경우가 발생하면 매매가 발생하지 않는게 약점이죠. 상단과 하단이 한번 형성된 후 계속 그 사이를 왔다 갔다하면서 상단과 하단을 터치하지 않으면서 가격만 계속 오르거나 내리는 경우가 가끔 있습니다. 그럼 그날 수익은 제로 인 거죠. 지금 이 공식은 제 프로그램중 ETF자동매매 프로그램에도 적용이 되어 있습니다. 이상적인 상황에서 이상적인 수익을 가져 주지만 급변 구간이 문제 입니다. 급변 구간의 해답은 앞 5장에 있는 내용을 참고 바랍니다. 하지만 sma1200_degrees의 경우 가격의 급변 보다는 에너지(돈의 수급)의 총량에 더 가깝다고 봐야 합니다. 급등시 급등 신호가 감지 되지만 전체 기간중 앞 15~30%에서 최고가가 형성됩니다. 그렇다고 매도를 하게 되면 그 순간 더 상당으로 달아 날 수도 있기 때문에 sma1200_degrees가 40º를 넘는 경우는 일단 매매를 멈춥니다. 50º가 넘었다면 무조건 멈춰야 합니다.
3. 기존의 방식중 절대하지 말아야 하는 방법들
1. 변동성 돌파 전략
이 전략은 주식전용 전략 입니다. 절대로 코인에 적용하면 안됩니다. 주식에도 적용하기가 그렇습니다. 코인은 24시간 체재입니다. 절대로 변동성 전략이 통할리 없습니다. 주식에서도 이 전략은 한달안에 거지되기 쉽상입니다. 요즘 주식은 아고점저(아침에 고점 점심때 저점)의 시대 입니다. 함부로 변동성 돌파 전략을 사용하면 아침에 고점에 물려서 오후 3시20분에 매도 되어 손실을 기록하게 됩니다.
2. MACD 오실로스코프 매매
이 매매 전략은 12, 30, 15 정도의 값으로 macd를 생성하고 하루 거래 발생 건수를 고려하여 배율을 조정하면 어느 정도의 수익을 보장합니다만 폭락장에서는 전혀 맞지 않습니다. 5월~7월사이에 코인 가격이 반토막이 난 것을 생각하면 지금은 깡통이겠죠?
3. 주식 보조 지표가 코인에서는 안맞는 이유
어떻게 보면 당연한 이야기 입니다. 기존의 매매 방식은 주식의 것이고 주식의 경우 9시부터 3시반까지만 거래가 되고 거래가 끝나고 5시쯤에 찌라시가 돕니다. 지금은 기존의 보조지표 매매도 전혀 맞지 않는게 주식 시장입니다. 그런데 그 보조지표가 코인에서 맞을 가요? 저는 모든 지표를 거의 새로 만들었습니다. 주식에서 통용되던 보조 지표들은 코인의 것이 아니니까요?
4. 마치며
수학자들 중에서는 미지의 소수를 찾는 작업을 평생연구하는 사람들이 꽤 많다는 말을 들었습니다. 게임의 법칙으로 노벨 경제학상을 탄 수학자 존 내시 박사도 소수에 어떤 공식이 있을 것이라며 평생을 받쳤지만 정작 친구들과 여자 꼬시기 방법을 재미로 연구한 게 노벨을 상을 받게 되었습니다. 기존의 확률은 존재하는 것에만 적용을 하지만 존 내시 박사의 게임에 법칙에서는 100명의 여자 중 최고의 신부를 고려는 방법으로 30명을 일단 만난 다음 차회 부터는 지금까지 만난 사람중 1이라도 나은 최고의 사람을 만난다면 무조건 결혼하는 법칙 즉 모수가 100일 수 없는 확률을 완성할 수 있는 방법을 제시합니다. 물론 소수를 구하는 공식 따위는 만들지 못했습니다. 일부 수학자는 소수가 짧은 주기와 긴 주기를 간격으로 해서 계속 반복되고 있다는 것은 밝혔지만 역시나 공식으로 이것을 증명하지는 못했습니다. 소수를 찾는 이론은 다양하게 많지만 지금의 슈퍼컴퓨터로도 다음 소수의 위치를 밝히지는 못했습니다. 근데 이 무모한 짓은 왜하는 것일까요? 우리처럼 주가나 비트코인의 가격을 예측하는 게 더 정상적이지 않을까요?
처음 Bitcoin 자동 매매 프로그램을 개발하고 벌써 5개월이란 시간이 흘렀네요. 자동 매매 프로그램의 시작은 주식이였지만 처음 성적은 별로 좋지 않았습니다. 그 때 배운게 인터넷에 떠 있는 소스는 절대 믿으면 안된다 였습니다. 생각해 보면 자동 매매 프로그램을 개발하시는 분들 대부분은 각자의 철학과 전략이 있기에 다른 어떤이와도 생각이 일치할 수도 없거니와 계속 변경되는 환경에서 이전의 소스가 맞을 리가 없었는데 말이죠. 그리고 나서 pyBithum이라는 python lib가 있다는 것을 알게 되었습니다. 고민도 할거 없이 나의 첫번째 자동 매매 프로그램은 그렇게 단 몇시간만에 탄생하게 되었습니다. 하지만 운영하면서 계속되는 원인을 알 수 없는 에러를 debugging하면서 Bithum API 자체 결함이 많다는 것을 서서히 눈치챘습니다. pyBithum lib는 그저 껍데기 일뿐 Bithum API를 호출하는 구조였던 거죠. 결국 Bithum API가 개선 되지 않는 이상 이 문제들은 해결될 수 없다는 것도 알게 되었습니다. 그러면서 각 거래소별 API에 대한 이야기를 다른 블로그를 통해서 알게 되었습니다. 그나마 Bithum API가 업계에서는 괜찮은 편이라는 거죠. 음 이거 실화냥? ㅠㅠ; 비싼 수수료에 영세업체 수준의 API 이것이 저의 생각입니다. Bithum 관계자가 이 글을 보면 저에게 소송을 걸까요? 그렇다면 이 문장을 수정해야 겠네요. 아실지 모르지만 우리나라에는 '사실즉시 명예훼손'이라는 법이 있습니다. 비록 그 내용이 '사실'이라 해도 그 내용을 공공에 게시하여 당사자의 명예를 훼손한다면 형사 처벌을 받는 법입니다. 헌법에 크게 위배된다고 생각한 많은 사람들이 헌법 소원을 했지만 작년 가을 헌제에서 '합헌 결정'이 났습니다. 민사로 충분히 처리가 가능하지만 형사처벌 조항이 있어 이중 처벌의 위험성이 있는데도 말이죠. 무엇이 무서웠을 까요?
2. Bithum API의 근본적인 문제점
1. version 정보 없음.
저도 현역 프로그래머로써 이 곳 저 곳을 다니면서 소위 RestAPI라는 것을 개발하고 있습니다. 처음에는 표준이 뭔지도 몰라 여기 저기 똥을 싸고 다녔지만 하다가 보니 저기는 왜 저렇게 했는지 여기는 왜 이렇게 했는지가 하나 둘씩 보이기 시작 했습니다. 그러면서 가장 먼저 눈에 띈게 바로 version정보 입니다. API path 중간에 (예시 : '/api/v1/info/user_transaction') 버젼 정보를 표시하고 있다는 거죠. 혹시 tensorflow를 사용해 보신 분이 계신가요? tensorflow v1에서 v2로 되면서 거의 천지개벽 수준으로 api변경이 되었습니다. keras의 위치가 중요하게 되면서 기존 v1의 기능은 대폭 축소 되고 모든 것을 keras에게 위임하는 형식으로 소스가 변경되고 간략화 되어 기존 v1소스는 폐기의 수준이 되었습죠. ㅠㅠ
from tensorflow.compat import v1 as tf tf.disable_v2_behavior() tf.random.set_random_seed(seed)
위 처럼 해주지 않으면 v2로 처리가 되어 거의 모든 함수에서 에러가 발생합니다. 눈치 채셨나요? 지금 거래소 API중 어떤것도 version 정보가 없습니다. (지금은 Upbit API로도 개발 중인데 Upbit API에는 버젼 정보가 있더군요. Upbit는 모기업이 KAKAO라 대기업의 냄새가 납니다.) 중간 중간에 실 운영기 소스를 수정하고 아무런 공지도 없습니다. 갑자기 잘 돌던 프로그램에서 type오류가 납니다. 원인은 API의 변경으로 리턴값이 바뀐겁니다. 현 체제로는 방법이 없는 거죠.
2. 오류 코드 묶음 처리
모든 API는 정상적으로 아주 잘 만들어 진 코드라고 해도 에러가 발생합니다. 정확하게는 예외사항이죠. 프로그래머도 컴퓨터도 어쩔 수 없는 사항이 발생한다는 거죠. 그런 때를 대비해서 오류코드가 있는 거죠. 제가 가장 황당했던건 Bithum API를 사용하면서 5500 에러와 5600에러 속에 수 많은 종류의 오류가 코드 없이 묶음으로 존재한다는 거였습니다. 사실 상당 수의 에러는 오류 처리를 할 필요도 없는데 말이죠. 아 그렇군 하는 정도면 되는데 말이죠. 근데 몇몇 프로그램에 아주 critical한 오류가 같이 섞여 있다는 게 문제 인거죠. 지금 제가 운영하고 있는 자동 매매 프로그램의 trading 부분 소스는 방어코드의 총망라 입죠. 오류코드가 세분화 안되어 있으니 프로그램에서 다 방어를 해야 한다는 느낌. 뭐 그렇습니다.
3. 운영 유지만 version up은 언제쯤?
사실 초기에는 Bithum에 몇 번 전화를 했었습니다. 전화 받는 분이 자기네 회사 오류코드 체계도 모르시더군요. 딱 봐도 전문 텔러가 아닌데 말이죠. (저는 초기에 콜센터 프로그램만 5년을 넘게 했었습니다. 전화 응대만 들어도 전문 텔러 인지 아닌지 알 수 있습니다.) 운영이나 개발인력의 수준을 눈치 채는데는 그리 많은 시간이 필요하지 않았습니다. 군데 군데 보이는 critical한 문제가 과연 고쳐 질까? 마치 창문 없는 집을 보고 '저 집에 창문은 어떻게 낼 수 있을까?' 고민하는 수준 이랄까요?
3. 나의 Bithum API 극복기
1. 주문량이 사용가능 KRW를 초과하였습니다.
해쉬태그로 뭘 달까 고민할 필요도 없이 '주문량이 사용가능 KRW를 초과하였습니다.'를 선택했습니다. 다른 블러그나 게시판에 아주 논쟁이 뜨겁습니다. 어떤 사람은 자기는 발생하지 않는데 난다고 한다고 하고 저 같은 경우는 계속 발생합니다. 제가 알아 낸 사실은 총 현금 보유 금액의 85%만 거래가 가능하다는 겁니다. 확실히 버그라고 하기에는 어딘가에 하드코딩되어 있는 뭔가가 있는 것 같습니다. 저 같은 경우는 보유 KRW의 85%를 구해서 여러번 분할 매수를 하게 프로그램 되어 있습니다. 그래서 계속 매수 하다 보면 결국 보유 현금의 100%까지 매수가 가능 합니다. 물론 최소 거래 금액과 0.0001 미만의 코인은 매수 되지 않습니다. (지금 up-bit 계좌로도 프로그램을 만들고 있는데 upbit는 최소 거래 금액이 bithum보다는 크지만 그것은 일회 거래금액의 단위이고 소수점 제약등은 존재하지 않습니다.)
balance = get_balance() #잔고 조회 if balance is not None: self.logger.info("잔고조회: %.5f %.5f %.2f %.2f", balance[0], balance[1], balance[2], balance[3]) krw = balance[2] #구매 가능 보유 금액
buy_krw = buy_price * unit #구매할 krw를 계산
remind_krw = krw - buy_krw #잔여 금액 계산
possible_krw = krw
if remind_krw <= buy_krw * 0.15: # 정액쿠폰 구매와 상관 없이 수수료 계산
possible_krw = krw - buy_krw * 0.15
unit = possible_krw/buy_price #구매 수량 계산
unit = int(unit * 10000)/10000 #unit은 소수점 네자리 아래 삭제 처리
order = bithumb.buy_limit_order(ticker, buy_price, unit, payment_currency="KRW") #매수 주문
if order is not None and type(order) is tuple:
self.logger.info("order success:%s, timing_price:%d, buy_price:%d"
% (str(order), timing_price, buy_price)) self.last_order_id = order;
for i in range(0,19):
resp = self.order_detail(order)
self.logger.info("order detail : " + str(resp))
if resp is not None and resp.get('status') == '0000':
orderStaus = resp.get('data').get('order_status')
if orderStaus == 'Completed':
slack.chat.post_message(slackkey.SLACKER_CHAN, time.ctime() + ":`order detail : " + str(resp) + "`")
break
return
클래스로 구현된 trading 모듈을 간략화해서 붙이는 거라 소스중간에 self가 보이는 부분 양해 바랍니다. 소스를 저렇게 고치고 나니 그 후 '주문량이 사용가능 KRW를 초과하였습니다.' 오류는 발생하지 않았습니다. 시장가 주문에서도 지정가 주문에서도 동일한 부분이 필요 합니다. 시장가 주문을 할 경우는 orderbook의 가장 첫번째 ask값을 buy_price로 해서 계산하면 됩니다. Bithum에서 수정한다면 거래를 태우기 전에 수수료를 먼저 검사해서 (아마도 app에서는 이 부분이 수정되어 있는 것 같습니다. app상에서는 이런 오류가 한번도 없었습니다.) 수수료 무료 고객은 수수료 부분까지도 구매가 가능하게 api를 수정하면 될 것 같습니다. Bithum에서 수정이 안된다면 우리는 계속 위의 소스를 유지 해야 겠죠.
2. 홈페이지 API 문서에는 있지만 pyBithum에는 없는 API들
혹시 pyBithum에 없는 API를 직접 함수로 구현하려고 HttpRequest를 사용하려고 시도하신 분들이 있을 까요? 제 생각에는 아마도 안되실 겁니다. 이유는 public API는 아무 상관 없이 개방되어 있지만 ( public과 private는 같은 함수라도 정보 조회 건수가 다른건 아실 겁니다.) private는 HttpRequest Header에 HMAC 값이 있습니다. 혹시 알고 계셨던 분들도 있으신가요? HMAC 계산은 아주 복잡하고 까다롭습니다. 하지만 pyBithum에는 이미 HMAC계산이 다 되어 있습니다. 아래 소스를 보시죠
from pybithumb.core import BithumbHttp
http = BithumbHttp(key.con_key, key.secu_key) #API KEY와 SECU KEY로 http초기화
url = '/info/user_transactions' #API 문서에 있는 url 값
#주의 : 중요한 것은 앞쪽에 있는 '/'가 없으면 type 에러 발생함.
try:
resp = http.post(url, offset=offset, count=count, searchGb='2', order_currency=self.ticker, payment_currency='KRW')
print("user_transactions:" + str(resp))
if resp != None and resp['status'] == '5600':
return None return resp
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
print("user_transactions -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
몇가지 import가 더 있지만 충분히 알 수 있는 내용이라 생략 했습니다. 생각보다 간단하죠? pyBithum에는 이미 이런 내용이 다 반영이 되어 있습니다. 예를 들면 Bithum API문서에는 Stop-Limit라는 기능이 있습니다. 지정가로 호가가 있으면 그때마다 매수를 하게 지정하는 함수 인데 pyBithum에는 아직 기능이 없습니다. 아마도 제 생각에는 pyBithum은 더 이상의 버젼업이 없을 것 같습니다. 이 기능을 구현하려면 url부분에 '/trade/stop_limit' 를 넣고 해당 Request Param중에 apiKey와 secretKey를 제외한 나머지 부분중 필수 값을 채우고 필수가 아닌 값은 보고 판단하시면 될 것 같습니다.
4. 마치며
Bithum관계자에게 간곡히 부탁드립니다. 만약에 혹시라도 이 게시물을 보신다면 '사실즉시 명예훼손'으로 고소하지 말아 주세요. 하시기전에 저에게 email(yubank@naver.com)한통이면 이 글 중 명예 훼손이 되는 부분은 전부 삭제 처리 하고 다른 프로그램에 필요한 내용만 남겨 두겠습니다. 그 마저도 불편하다고 생각 하시면 전체를 비공개로 전환하겠습니다. 아직 저의 블로그 방문자는 10명 내외로 미미한 수준입니다. 혹시라도 이곳에서 이 글을 보신다면 제가 Bithum을 비방하려는 목적이 아님을 아실 겁니다. 저도 처음에는 '주문량이 사용가능 KRW를 초과하였습니다.' 오류로 프로그램에 중간에 멈추는 현상이 아주 잦았습니다. 원인을 알고 수정하고 주문을 여러번에 나눠서 하게 수정을 해서 겨우 해결을 했습니다. 아직도 이 문제를 해결하지 못하신 분들도 인터넷 게시판을 디지다 보면 많은 것을 알고 있습니다. 새로 시작하시는 분들도 상당 수 이 문제에 봉착 하시라 생각 됩니다. 그리고 Bithum뿐만 아니라 현재의 우리나라 Bitcoin 거래소들의 출발이나 현재의 모습이 어떨지 왜 그랬는지를 알고 앞으로가 어떨지도 알고 있습니다. 현재 시점 수 많은 거래소가 정부 가이드를 못 맞춰서 대표자 횡령혐의로 입건 되거나 폐쇄의 길을 걷고 있다는 뉴스는 쉽게 접할 수 있습니다. 그래도 대표 4개 거래소는 끝까지 살아 남았으면 하는 바램이 아주 큽니다. 정부에서는 증권거래소와 같이 중앙 거래소와 증권사를 두는 방식의 개편을 준비 중인 것 같습니다. 그렇게 되는 데만도 족히 4~5년은 걸릴 것 이고 은행들은 새로운 BIS기준 때문에 일부 Bitcoin 거래소의 전용계좌 개설 및 기존 계좌를 폐쇄하려고 하고 있죠. 그럼 아마도 Bitcoin거래소는 재계순위 4위까지만 살아 남고 나머지는 거의 다 폐쇄될 것으로 보입니다. 그 이후에는 진짜 제대로 모습을 갖춘 거래소들이 다시 생기겠죠. 사실 Bitcoin의 운명도 불투명합니다. 미국은 달러연계 암호화 화폐를 준비중입니다. 사실 미국이라는 나라는 남미의 국가들에게는 소리없는 죽음의 침략자입니다. 과거에는 전쟁으로 영토를 침략했다면 지금은 금융으로 타 국가의 이익을 소리도 없이 점령합니다. 수 많은 사람들이 죽음으로 내 몰리지만 저희는 알 수도 없습니다. 이유는 기축통화인 달러를 자기 나라의 이익을 위해 맘데로 운영을 하면서 남미의 국가 나 또는 폐그제를 운영하는 여러 나라에 막대한 피해를 입히고 있습니다. 그런데 이 영향을 안 받는게 Bitcoin이죠. 그래서 미국은 또 다른 침략인 달러 연계 암호화 화폐를 만들려고 합니다. 그리고 우리나라도 원화 연계 암호화 화폐(소위 말하는 전자 화폐)를 개발하고 있습니다. Bitcoin은 악용되는 사례도 많습니다. 수 많은 나라에서 납치범들이 몸값을 요구하는 수단으로 Bitcoin을 사용하고 있고 마약거래 및 인신매매에도 사용되고 있죠. 그래서 부자들 중 워랜버핏 같은 사람은 Bitcoin혐오 주의자 중 한명이기도 합니다. 지금이 Bitcoin및 거래소들이 중요 갈림길이라고 봅니다. 4~5년 후에도 살아 남으려면 과연 무엇을 준비해야 할까요?
어떤 파도타기를 좋아하는 사람이 있다고 합시다. 보통의 파도는 너무도 잘 타지만 이 사람은 한계가 어디까지인지 궁금했습니다. 문제는 파도의 높이와 바람의 방향에 따라 잘못하면 파도를 타다가 죽을 수도 있다는 거겠죠. 파도가 아무리 높아도 바람이 세지 않다면 별 문제가 없을 거고요. 바람의 방향도 자신의 방향인지 반대 방향인지에 따라 파도의 높이가 문제가 안될 수도 생명이 위태로울 수도 있는 거죠. 바람의 방향이 내륙 쪽이고 파도가 높다면 즉시 파도타기를 중지하고 휴식을 취해야 하지만 파도가 높고 바람의 방향이 바다를 향한다면 그것은 서퍼에게는 최고의 도전이 되겠죠. 눈치 채셨나요? 요즘 Bitcoin 시장이 위의 내용과 비슷합니다. 일주일 단위로 급등락을 하고 있습니다. 보통 주말을 주기로 급락을 하고 주 후반에 급등을 했다가 또 어느샌가 급락을 합니다. 폭은 대략 이더리움 기준으로 약 40만 원 선을 왔다 갔다 하지만 어느새 이더리움 가격은 최고점 대비 반토막이 났고 비트코인도 맞찬가지 입니다. 현재 시점 기준 비트코인은 반등했지만 4천이 안 되는 선에서 박스권을 만들고 있습니다. 다시 파도타기 이야기로 돌아간다면 바람의 방향이 언제 바뀔지 파도의 세기는 얼마나 되는지(바람의 세기와 비례하겠죠?) 파도의 높이는 어느 정도 되는지 (미리 예측하는 것이 아니라) 현시점의 변화만 알아도 얼마든지 파도타기에 도전하는 것은 무리가 없겠죠? 다시 비트코인 세계로 돌아온다면 이 모든 것을 결정하는 것은 무엇일까요? 사람들은 이동평균선으로 대충의 추세를 예측하지만 컴퓨터(프로그램)는 불행히도 인간이 보는 이동평균선을 볼 수 없습니다. 대신에 점으로 보는 거죠. 근데 문제는 점으로는 앞의 추세를 판단할 수가 없습니다. 여기서 미적분이 필요합니다. 문과분이나 수학을 잘하지 못했던 분들은 미적분이라는 소리에도 놀라시겠지만 제가 하려는 미적분은 실제로는 미적분과 거리가 멀다고 할 수 있습니다. 그냥 대충의 미적분인 것입니다. 왜냐하면 컴퓨터는 0 또는 1만 이해할 수 있고 프로그램에서는 true와 false만 이해를 할 수 있으므로 그에 대입되는 값의 정확도는 그리 중요하지 않습니다.
2. 자동매매 분석에 미적분이 필요한 이유
먼저 미분에 대하여 여러분은 예전 고등학교 시절 무엇이라고 기억하고 계신가요? 왜 미분을 해야 하는지에 대한 내용이나 미분을 하는 방법에 대하여 배우신적이 있으신가요? 지금 우리가 하려는 미분은 이전 수학 시간에 배우던 그런 어려운 미분이 아닙니다. 인간은 모든 데이터 및 주위 환경을 이해하기 위해서 아날로그 데이터를 사용합니다. 이전에는 모니터도 아날로그 음악도 아날로그 모든 것이 아날로그였지만 현재는 모든 것이 디지털입니다. 그럼 여러분 아날로그와 디지털의 차이는 무엇일까요? 예로 제가 처음 컴퓨터 프로그래머로 일했을 때 제가 주로 했던 일이 콜센터의 지능형 ARS 즉 IVR이라는 시스템을 설치하고 프로그래밍하는 일이었습니다. 이때 아날로그인 음성을 디지털로 만드는 것을 샘플링이라고 하고 주로 1초에 8000번 샘플링한 데이터를 사용하여 프로그래밍 해었습니다. 하지만 아날로그의 절대 끝은 존재하지 않아서 인간의 가청 주파수인 20000Hz 이상의 데이터는 버리고 샘플 했습니다. 즉 주변의 소리도 1초에 8000번만 높이를 기록하면 다시 소리로 변환할 때는 정상 소리와 구분이 안 가고 사람이 알아들을 수 있습니다. 요즘은 음악 녹음할 때는 198000번 정도의 초당 샘플링을 합니다. 그러면 사람은 거의 원본 녹음과 디지털 음을 구분하지 못합니다.
다시 비트코인의 세계로 돌아 와서 우리 사람은 쉽게 이해할 수 있는 이동평균선(MA)을 컴퓨터(프로그램)가 이해하고 학습할 수 있게 할 수 있을 까요? 위 이야기의 파도타기처럼 컴퓨터가 어떤 이동평균선이 위험한지 어떤 게 안전한지 폭락 후 멈출 때 현상은 무엇인지 폭등이 시작된 것은 어떻게 판단할지 폭등은 언제쯤 멈출 것이며 폭등 후의 행동은 무엇일지 컴퓨터가 판단할 수 있는지에 대한 이야기입니다.
다시 저의 초기 프로그래머 시절로 돌아가서 소리를 8000번 샘플링하는 것을 PCM(Pulse-code modulation)이라고 했습니다. 여기서 중요한 것은 8000번 샘플링에는 일정한 주기가 있다는 것 입니다. 컴퓨터가 우리가 사는 3차원의 세계를 이해하려면 자신이 있는 1차원의 세계의 데이터로 변환하는 일이 필요합니다. 혹시 Deep learning공부를 하신 분들이 계신가요? 딮러닝 공부를 하신다면 무슨 게이트 무슨 게이트 시그모이드니 뭐니 하는 것들을 가만히 생각해 보시면 결국 다차원의 데이터를 1차원의 데이터로 변환하는 가정이라는 것을 아시게 되실 겁니다. 결국은 컴퓨터는 1차원 데이터 외에는 이해 불가라는 거죠. 다시 고등학교 시절로 돌아가서 미분을 다시 배운다면 미분은 다차원의 데이터를 1차원 데이터로 변환하는 가정이라고 배우신다면 좋을 듯합니다.(왜 그때는 수학을 어렵게만 가르쳤는지 저는 이해가 잘 안 됩니다.) 이게 뭔 말이냐 하면 우리가 분석하려는 이동평균선은 고차원 방정식의 곡선입니다. 변화무상하고 매 순간 변화하지만 일 순간은 점(dot)이라는 사실이죠. 이 점(dot)은 바로 컴퓨터가 이해할 수 있는 1차원 데이터 입니다만 문제는 이 점(dot)이 완벽한 데이터가 되려면 방향이 필요합니다. 그래서 제가 생각한 게 바로 각도입니다. 곡선의 한 점을 미분하면 그 지점의 각도를 구할 수 있습니다. 혹시라도 고등학교 수학을 놓치지 않으셨다면 다들 알고 있는 것일 겁니다.
간단하게 미분식을 표현한다면 앞의 식처럼 표현 하겠지만 정식적인 표현은 'f(x) = 기울기*x + 절편' 이런 식의 식이 나올 겁니다. 하지만 우리가 필요한 것은 기울기만 필요합니다. 시간 단위로 움직이는 평균 이동선의 값의 변화는 pandas를 이용하면 아주 쉽게 구할 수 있습니다. pandas DataFrame을 df라고 하고 평균 이동선을 sma120(120개 이동평균선)이라고 하면 dy = df.sma120 - df.sma120.shift()로 쉽게 구할 수 있습니다. 그렇지만 시간의 변화 값을 구하는 것은 실제로는 불가능합니다. 하지만 상관없습니다. 우리는 대충의 근접 치를 구하는 것이지 딱 이 값 이런 식의 값을 구하는 것이 아닙니다. 우리는 컴퓨터 프로그램에서 사용할 수 있는 오차가 있어도 다른 값과 커플링 되지 않으면서 비교가 가능하고 방향성을 가지는 값만 구하면 됩니다. 그래서 저는 dt값을 대충 3*60 정도로 하기로 했습니다. <제가 살다 보니 사람들 마다 문과 머리와 이과 머리가 따로 있는 것 같더군요. 제가 위처럼 dt를 대충 3*60이라고 정한다고 하면 이과 머리는 절대로 이해를 못합니다. 근데 수학을 잘 못하는 문과생들은 "그래"하고 금방 수긍하죠.> 그 다음 다시 수학입니다. 그냥 인터넷만 뒤지면 나오는 기울기로 각도 구하는 공식입니다. python으로 식을 구하면
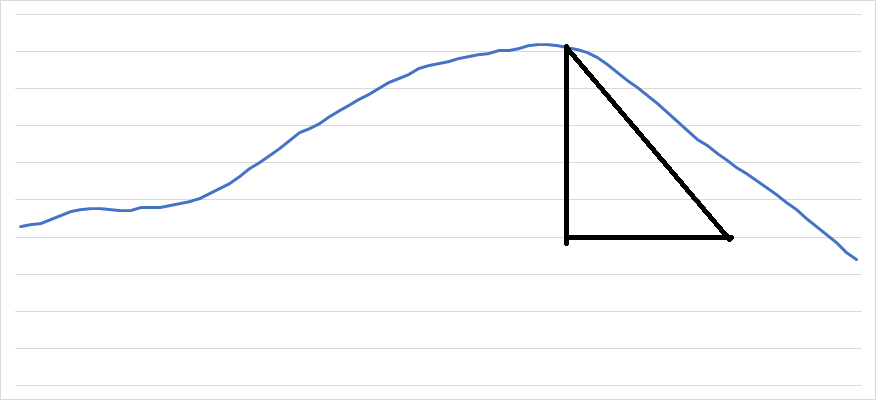
2장에 나오는 class Auxiliary 에 위 부분을 추가하면 이제는 각 보조 지표들에 대하여 하락 중인지 상승 중인지를 알 수 있습니다. 저 같은 경우는 이 블로그 초기에 5분 데이터를 버리고 지금은 1분 데이터를 사용하고 있으며 1200분의 이동평균선(이하 sma1200)을 주로 이용하고 있고 이 값은 현재 급변하는 비트코인 시장에 너무나도 잘 맞고 있습니다. 신기할 정도입니다. sma1200의 각도인 sma1200_degrees는 위의 식을 잘 응용하신다면 쉽게 구하셨을 거라고 생각합니다. 그리고 제 프로그램에 위의 식을 이용하여 sma1200_degrees가 30 º 를 초과하면 급등 구간으로 정의하고 40 º 를 초과하면 급급등 구간으로 정의했습니다. 그래서 30 º초과하는 경우 조건식이 뭐건 상관없이 무조건 매수하게 했습니다. 40 º 를 초과하면 절대로 매도를 안 하는 거죠. 왜냐면 계속 오를 테니까요? 하지만 여기에는 문제가 있습니다. 우리가 파도를 타는 사람이라고 생각하면 무엇보다도 바람의 방향이 중요합니다. 바람의 방향을 무시하면 생명과 직결되는 문제가 발생합니다. 바람의 방향이 바뀌면 바로 모든 것을 버리고 해변으로 나와야 하죠. 순풍이라고 신이 나서 죽음이 다가오고 있는지 모르고 즐기고 있다면 죽음의 신이 바로 옆에 있는데 춤을 추는 꼴이겠죠. 그래서 제가 생각한 값이 곡선의 밑면과 닫는 넓이입니다. 밑변은 840분 동안의 최저가를 사용했습니다. 그리고 우리는 위의 각도를 알고 있기 때문에 곡선에서 90 º로 내린 선과 곡선의 기울기를 이용한 각도인 sma1200_degrees와 840분 동안의 최저가를 이용하면 하나의 직각 삼각형을 구할 수 있다는 것을 쉽게 이해하실 겁니다.
대충 옆의 그림처럼요 이 삼각형의 넓이를 대충 저는 minus_range라고 정했습니다. 이 값은 굉장히 큰값이 나옵니다. 이 값을 이용하면 파도의 힘과 방향을 알 수 있지만 역시나 값이 너무 큽니다. 그래서 다시 한번 이 값의 이동평균선을 구했습니다. 왜냐하면 이제는 어떤 이동평균선이 와도 컴퓨터(프로그램)는 이해할 수 있기 때문이지죠 아래 python코드를 보시면 아실 겁니다.
직각삼각형의 넓이의 이름은 minus_range이고 이값을 이동평균 한 값은 mrma로 정했습니다. 그리고 다시 mrma의 증감 값을 구하고 이 값의 각도를 다시 구했습니다. 이 값을 mrdeg로 했는데 사실 이 값은 그리 중요하지 않습니다. 딮러닝의 시그모이드(다차원의 값을 0과 1로만 표현하게 변환하는 모델) 같은 역할을 하는 값입니다. 이 값이 양수 이면 계속 상승 중인 거고 이 값이 음수이면 하락 반전한 것입니다. 즉 sma1200_degrees가 30을 넘어가면 가격이 얼마이던지 중요하지 않고 무조건 매수를 합니다. 다면 sma1200_mrdeg가 양수 일 때만 인 거죠. 그러다가 상승 에너지가 점점 약해지면 sma1200_mrdeg가 음수로 전환됩니다. 자 이젠 파도타기를 멈추고 해변으로 탈출해야 하는 시기입니다. 즉 가지고 있던 모든 비트코인을 매도하고 잠시 해변으로 나와 파도를 감상하는 타임을 가지는 거죠. ㅋㅋㅋㅋㅋ 저는 이 공식을 만들고 급락할 때도 이익을 내고 있습니다. 왜냐하면 급락도 위의 식의 반대가 되는 거죠. 급락 구간도 두 구간으로 나누고 -30 º 에서는 매수와 매도를 계속하게 했습니다. 그러다가 -40 º가 되면 급락이 시작되는 것이기에 무조건 매도합니다. 이때는 수익률이 약간 손해를 봅니다. 이유는 사실 이때가 최저가인지 아니며 지옥의 문 앞인지 저도 컴퓨터도 예측이 불가능하기 때문이죠. 이건 어떤 누구도 예측이 불가합니다. 저는 이번 하락 구간에서 -40 º가 하루를 넘기는 적도 보았습니다. 어쨌든 계속 폭락하던 값이 언제 멈출지는 이제 sma1200_mrdeg를 이용하면 쉽게 알 수 있습니다. sma1200_mrdeg 값이 점점 줄다가 양수로 변하면 무조건 매수를 시작합니다. 아주 빨리 올인을 해야 하죠 그리고 상승장을 기다립니다. 대부분은 급락 후는 바로 급등이고 일부는 급락 후에는 제가 이름 붙인 '렌딩 구간'이 발생합니다. 렌딩의 끝이 바로sma1200_mrdeg가 양수로 변하는 순간인 거죠.
3. 마치며
이번 회차에서는 추상적인 개념을 설명하다보니 여러 세계관을 왔다 갔다 했습니다. 저는 1970년대 사람이라 다른 시대를 사신 분들과 저의 어린 시절(고교 수학 시절)이 많이 다를 수 있을 것으로 생각됩니다. 물론 저도 파도타기 세계관을 경험하지는 못했습니다. 다만 어린시절 본 '폭풍 속으로'라는 영화를 상상해 보았습니다. 주인공 키아누 리부스의 명연기가 생각나는 영화입니다. 은행강도를 잡으려 강도단에 잠입한 잠입형사역인데 익스트림을 즐기는 보니(패트릭 스웨이지)에 완전히 반해버려 보니의 꿈인 가장 큰 파도를 타는 꿈을 위해서 체포를 포기합니다. 영화 마지막 장면은 폭풍속 집채만 한 파도 속으로 보니가 뛰어들고 자니(키아누 리부스)는 체포를 포기하는 장면으로 끝이 납니다. 보니가 죽었는지 살았는지는 아무도 알 수 없습니다. 비트코인 투자를 하시는 여러분들도 이미 가상의 익스트림을 하고 있다고 저는 생각합니다. 저는 여러분들이 보니 같은 사람이 아니었으면 합니다.
혹시 이전 회차 에 결과에 실망하신 분들이 있으신가요? main.py 중간 쯤에 있는 add_macd의 수치를 약간 바꾸어 보았습니다. 변경 부분 bcondition.add_macd(12, 30, 9) 그랬더니
12, 26, 9와는 완전 다른 결과를 출력 하고 있습니다. 제가 이전 회차에서 왜 f(n)에서 f(x)를 찾는 작업 이라고 말씀 드린 이유를 위 그림을 보시면 잘 알 수 있습니다. 다시 돌아가서 macd의 기본 값이 왜 12, 26, 9일까요? 예전에 거래일은 6거래일 즉 토요일도 장이 열리던 시절이 있었습니다. 그럼 12는 2주 26은 한달 그리고 9는 2번주의 중간 정도 된다는 것을 아실 겁니다. 하지만 잘 생각해 보시면 bitcoin거래는 365일 24시간 계속 되는 거래 입니다. 애초에 12, 26, 9 값이 맞을 리가 만무 합니다. 그렇다고 12, 30, 9가 꼭 정답이라고도 할 수 없습니다. 계속적으로 값을 대입하다보면 일일 거래 건수와 수익률이 최적인 어떤 상태가 나올 겁니다. 우리는 그기를 찾으면 됩니다. 지금은 12, 30, 9로 값을 셋팅 하고 한번 진행 해 보도록 하겠습니다.
2. Bithumb 거래소 연동 하기
제가 시작한지 얼마 안돼서 경험이 그렇게 많은 편은 아닙니다. 하지만 Bithumb의 API나 시스템은 실명스럽기 그지 없네요. 하긴 지금 저희가 사용하려는 pybithumb lib는 Bithumb의 정식 lib는 아닌듯 합니다. 홈페이지 어디에도 이 lib를 사용하라는 말은 없습니다. 대신 rest api에 대한 가이드와 설명이 있습니다. 지금은 시간이 안돼서 rest api로 다시 lib를 제작할 수 는 없지만 실제 rest api에 있는 내용중 pybithumb에는 없는 것들이 있습니다. 이런 문제를 제치고 일단 api오류가 생각보다 많이 발생 합니다. 특히 get_balance함수(잔고 조회)의 경우 3번중 1번은 오류입니다. 또 다른 문제는 구조적인 문제 입니다. 이 문제에 직면하고는 bitcoin 자동 매매에 상당한 실망을 한 상태 입니다. 주식의 경우 풍부한 유동성과 함께 여러가지 체결방법과 가격대별로 자동으로 호가에 대한 단위와 구간이 있습니다. 하지만 bitcoin의 경우 이런 구간에 대한 설정이 상당히 엉성하고 형편 없습니다. 이런 부분까지 고려한 프로그램이 나와야 할 것으로 보입니다.
예를 들면 주식의 경우 주가가 만원 미만인 경우 100원단위 호가로 호가를 호출 한다면 만원 이상이 되면 자동적으로 호가 단위가 500원 단위 그 이상이 되면 호가 단위는 1000원 이렇게 계속 호가 단위가 바뀌는 구간이 있습니다. 하지만 bitcoin은 그런 구간이 없어서 호가 사이 금액 차이가 엄청 납니다. 그래서 자동매매가 정상적으로 동작하려면 시장가 매매가 되어야 하는데 이 시장가 매매가 호가 사이 금액 차이 때문에 우리가 원하는 금액으로 매수가 안되는 단점을 보입니다. 이를 보완 할 방법은 차차 생각 해 보도록 하겠습니다.
소스 내용(BithumbTrade.py)
import pybithumb
import math
import time as datetime
import sys
import os
class BithumbTrade:
def __init__(self, bithumb, logger, ticker):
self.bithumb = bithumb
self.logger = logger
self.ticker = ticker
###잔고 조회
def get_balance(self):
for i in range(2):
balance = self.bithumb.get_balance('BTC')
self.logger.info("잔고조회:" + str(balance))
#수익률 구하기
if balance is not None:
return balance
else:
self.logger.warn("Bithumb API오류")
datetime.sleep(1)
def buy_crypto_currency(self, timing_price):
while True:
try:
balance = self.get_balance() #현금 보유 금액
krw = balance[2] - balance[3] #현금 보유 금액
possible_krw = krw * 0.9
possible_krw = possible_krw - (possible_krw % 1000) #천원 단위로 매매함.
if possible_krw < 500:
self.logger.info("보유 금액이 너무 작습니다.:%.2f" % krw)
return
while True:
orderbook = pybithumb.get_orderbook(self.ticker) #호가창 정보
self.logger.info("orderbook:%s", str(orderbook))
sell_price = orderbook['asks'][0]['price']
sell_volume = orderbook['asks'][0]['quantity'] #quantity
if sell_price > timing_price:
sell_price = timing_price
unit = possible_krw/float(sell_price) #호가창 가격에서 첫번재 가격으로 가능 금액을 나눈다.
unit = math.trunc(unit * 10000) / 10000 #소수점 네자리 이상 버림.
self.logger.info("%s --> unit : %.5f : sell_price: %.2f sell_volume: %.5f" % (self.ticker, unit, sell_price, sell_volume))
self.logger.info("%s --> unit : %.5f : sell_price: %.2f" % (self.ticker, unit, timing_price))
if(unit == 0):
self.logger.info("보유 금액이 너무 작습니다.:%.2f" % krw)
return
elif(unit < 0.001):
self.logger.info("unit이 최소단위보다 작습니다.: %.4f", unit)
return
sell_price = int(sell_price)
self.logger.info("timing_price:%d, unit:%.5f, possible_krw:%.2f" % (sell_price, unit, possible_krw))
order = self.bithumb.buy_limit_order(self.ticker, sell_price, unit, payment_currency="KRW") #매수 주문
if order is not None and type(order) is tuple:
self.logger.info("order success:%s, timing_price:%d, sell_price:%d" % (str(order), timing_price, sell_price))
return
elif order is not None:
self.logger.warn("order `fail:" + str(order))
if order.get('status') == '5500':
possible_krw = possible_krw - 10000 #만원씩 빼서 재 도전
unit = possible_krw/float(sell_price) #호가창 가격에서 첫번재 가격으로 가능 금액을 나눈다.
unit = math.trunc(unit * 10000) / 10000 #소수점 네자리 이상 버림.
self.logger.info("%s --> unit : %.4f" % (self.ticker, unit))
datetime.sleep(1)
continue
elif order.get('status') == '5600':
orderbook = pybithumb.get_orderbook(self.ticker) #호가창 정보
self.logger.info("orderbook:%s", str(orderbook))
sell_price = orderbook['asks'][0]['price']
unit = possible_krw/float(sell_price) #호가창 가격에서 첫번재 가격으로 가능 금액을 나눈다.
unit = math.trunc(unit * 10000) / 10000 #소수점 네자리 이상 버림.
self.logger.info("%s --> unit : %.4f" % (self.ticker, unit))
return
else:
datetime.sleep(1)
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
self.logger.error("buy_crypto_currency -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
datetime.sleep(1)
def sell_crypto_currency(self, timing_price):
while True:
try:
unit = self.bithumb.get_balance(self.ticker)[0]
if(unit == 0):
self.logger.info("보유 코인(%s)이 없습니다." % self.ticker)
return
orderbook = pybithumb.get_orderbook(self.ticker) #호가창 정보
self.logger.info("orderbook:%s", str(orderbook))
# order = bithumb.sell_market_order(ticker, unit, payment_currency="KRW")
sell_price = int(timing_price)
order = self.bithumb.sell_limit_order(self.ticker, sell_price, unit, payment_currency="KRW") #매수 주문
self.logger.info("sell_market: ticker: %s, unit:%.2f" % (self.ticker, unit))
if order is not None and type(order) is tuple:
self.logger.info("order success:%s, timing_price:%d" % (str(order), timing_price))
return
elif order is not None:
self.logger.warn("order fail:" + str(order))
return
else:
datetime.sleep(1)
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
self.logger.error("sell_crypto_currency -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
datetime.sleep(1)
위의 소스를 적용하기 전에 먼저 main.py가 있는 디렉토리에 private 라고 폴더를 하나 만듭니다.
혹시 git이나 외부 소스 관리 플랫폼에 소스를 올리더라도 이 private 폴더는 .gitignore에 추가 하여 BithumbKey.py파일이 안 올라 가게 조치 하시기 발랍니다.
그리고 main.py를 대폭 수정 했습니다.
소스 내용(main.py)
from getBithumbData import ScrapCurrBithum
from BithumbCondition import BithumbCondition
from BithumbTrade import BithumbTrade
import time as datetime
import sqlite3
import sys
import os
import logging
import logging.config
import json
import pybithumb
import private.BithumbKey as key
config = json.load(open('./logging.json'))
logging.config.dictConfig(config)
buy_func = lambda x, dataframe: x >= 2 and dataframe.loc[x, 'flag1'] > 0 and dataframe.loc[x-1, 'flag1'] <= 0 and dataframe.loc[x-2, 'flag1'] <= 0
sell_func = lambda x, dataframe: x >= 2 and dataframe.loc[x, 'flag1'] <= 0 and dataframe.loc[x-1, 'flag1'] > 0 and dataframe.loc[x-2, 'flag1'] > 0
BASE_BALANCE = 1000000 # 초기 투자금 100만원
# BASIC_FEES = 0.0005
if __name__ == '__main__':
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
dbname = "bithum5mMACD1.db"
sqlcon = sqlite3.connect(dbname)
bcondition = BithumbCondition(logger, BASE_BALANCE, buy_func, sell_func)
scb = ScrapCurrBithum()
bithumb = pybithumb.Bithumb(key.con_key, key.secu_key)
trade = BithumbTrade(bithumb, logger, 'BTC')
last_time = ""
krw = 0
while True:
try:
start_time = datetime.time()
###현재가 구하기
try:
price = pybithumb.get_current_price("BTC")
logger.info("현재가 : %.4f" % price)
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
logger.error("get_current_proce -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
###잔고 조회
balance = trade.get_balance()
logger.info("잔고조회:" + str(balance))
#수익률 구하기
if balance is not None:
rate = ((balance[0]*price + balance[2] - BASE_BALANCE)*100)/BASE_BALANCE
logger.info("수익률: %.2f %%" % rate)
#현재의 원화 잔고 얻기
krw = balance[2] - balance[3]
orderbook = pybithumb.get_orderbook("BTC")
logger.info("orderbook:%s", str(orderbook))
if orderbook is not None:
#최우선 매도 호가 구하기
asks = orderbook['asks']
sell_price = asks[0]['price'] #==> 최우선 매도 호가
sell_volume = asks[0]['quantity'] #quantity
unit = krw/float(sell_price) #==> 매도 수
logger.info("최우선 매도호가: %.2f 매도수량:%.5f 수량:%.4f" % (sell_price, sell_volume, unit))
df = scb.get_data()
bcondition.append_dataframe(df)
#전체 보조 지표를 포함하지 않고 개별 보조 지표를 사용하도록 하겠습니다.
bcondition.add_macd(12, 30, 9)
bcondition.add_moving_avg240()
df,timing = bcondition.sell_and_buy() #macd 계산
savedf = df.tail(1)
lastdata = savedf.loc[savedf.index.max()]
lasttime = lastdata['time']
close = lastdata['close']
sma240 = lastdata['sma240']
sma240_incli = lastdata['sma240_incli']
sma240vsclose = lastdata['sma240vsclose']
sma240clsmax = lastdata['sma240clsmax']
sma240clsmin = lastdata['sma240clsmin']
sma240clsminsig1 = lastdata['sma240clsminsig1']
sma240clsminsig2 = lastdata['sma240clsminsig2']
sma240clsmaxsig1 = lastdata['sma240clsmaxsig1']
sma240clsmaxsig2 = lastdata['sma240clsmaxsig2']
logger.info("마지막 데이터:" + str(lastdata))
logger.info("sma240:" + str([sma240, sma240_incli, sma240vsclose, sma240clsmax, sma240clsmin]))
logger.info("sma240:" + str([sma240clsminsig1, sma240clsminsig2, sma240clsmaxsig1, sma240clsmaxsig2]))
if sma240_incli >= 0 :
logger.info("sma240==> 상승 추세" )
else:
logger.info("sma240==> 하락 추세" )
if sma240vsclose >= 0:
logger.info("sma240 보다 상위 위치==> 상승 추세" )
else:
logger.info("sma240 보다 하위 위치==> 하락 추세" )
if lasttime == timing['time'] and timing['sellbuy'] == 'sell':
logger.info("매도 타이밍" + str(timing))
trade.sell_crypto_currency(timing['price'])
elif lasttime == timing['time'] and timing['sellbuy'] == 'buy':
logger.info("매수 타이밍" + str(timing))
trade.buy_crypto_currency(timing['price'])
get_time= datetime.strftime("%Y%m%d%H%M%S", datetime.localtime(lasttime/1000))
if last_time == "":
df.to_sql(name=dbname, con=sqlcon, if_exists='replace')
elif last_time != get_time:
last_time = get_time
savedf.to_sql(name=dbname, con=sqlcon, if_exists='append')
logger.info("MACD1 최종:")
logger.info(df)
strdt1 = datetime.strftime("%Y%m%d", datetime.localtime(df.loc[df.index.max()-2, 'time']/1000))
strdt2 = datetime.strftime("%Y%m%d", datetime.localtime(df.loc[df.index.max()-1, 'time']/1000))
logger.info("마지막1전: %s, 마지막:%s", strdt1, strdt2)
if(strdt1 != strdt2 ): #날짜가 변경되었다면
logger.info('자정이면 메모리를 일부 크리어한다.')
df = df.tail(df.index.max() - 12*24)
df.reset_index(drop=True, inplace=True)
end_time = datetime.time()
if (end_time - start_time) > 0 and (end_time - start_time) <= 5*60:
datetime.sleep(5*60 - (end_time - start_time))
except Exception as ex:
## NULL 데이터 인 경우 merge가 안된다.
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
logger.error("`add_closeminmax -> exception! %s ` : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
일단은 이 소스를 기반으로 운영하면서 수정이 필요해 보입니다. 지금 현재 Bithumb에서는 Trade에 두가지 매매 방법이 있습니다. 시장가 매매와 지정가 매매입니다. 주식의 경우 매매 방법은 총 12가지로 정부에서 매매방법에 대한 가이드를 하고 수정한 것들입니다. 같은 시장가 매매 라고 해도 지금의 coin 거래소의 방법들(Bithumb외의 다른 곳도 거의 비슷합니다.)과는 전혀 다르다고 보시면 됩니다. 우리가 트래킹한 수익률과 실제 매매의 수익률이 일치 할려면 현재의 시스템으로는 한계가 있어 보입니다. 현재는 지정가로 하면 매매가 안되고 시장가로 하면 손해가 발생합니다. 그래서 일단 240 이동 평균선(5분 데이터의 경우 10시간임)으로 추세를 예측하는 부분을 삽입했습니다. 이 후 데이터가 싸이면 이부분을 이용해서 언제 거래를 지속 할지 그리고 언제 지정가 매매를 할지 언제 시장가 매매를 할지를 판단해 보도록 하겟습니다.
3. 마치며
오늘 회차는 어떠셨나요? 제가 생각했던 것 보다 거래소의 수준이 한심한 수준이네요. 현재 1위 거래소는 upbit, 2위는 bithumb 3위는 코인빗 4위가 코인원 5위가 프로빗 익스체인지 라고 하네요. 제가 생각하는 주식과 코인의 가장 큰 차이는 주식의 경우 증권거래소를 비롯하여 중간에 많은 기관이 서로를 보조하는 기능이 있습니다. 코인의 경우는 그러한 기능은 간소하지만 그러다보니 문제점이 많이 보입니다. 어쨌든 그러한 문제는 우리 서서로 풀어야 한다는게 참 안타깝네요. 다음차에 데이터가 모이면 macd와 추세를 이용하여 현재의 문제점을 보안 해보도록 하겠습니다.