![]()
1. 들어가기 전에
혹시 예전 중고등학교 시절 배운 연역법과 귀납법에 대하여 기억을 하시나요? 수학 시간에 무언가를 증명하라는 문제가 나오면 대부분은 연역법을 사용하여 A=B, B=C 그러므로 A=C이다고 증명을 했을 것입니다. 하지만 가끔은 연역법을 사용할 수 없는 것들이 있습니다. 예를 들면 수열이 그렇습니다. f(n) = f(n-1) + 3이라는 수식이 주어 진다면 f(1)은 5라고 한다면 f(0)는 2가 되고 f(2) = f(1) + 3 = 8 .. 이런 식으로 증가하는 것은 알겠는데 그래서 f(x)는 뭐지? 수학을 잘하셨던 분들은 금방 f(x) = 3*x + 2 인 것을 눈치 채었을 듯합니다만 수학에 잰뱅이셨던 분들도 우리 주제를 읽어시는데는 아무 상관이 없습니다. 왜 장황한 이야기를 하느냐 하면 지금 우리가 하고 있는 python Bitcoin 자동매매 프로그램이 해야 하는 목표가 바로 f(n)식을 이용하여 f(x)식을 구해야 하는 일이기 때문입니다. 저는 1970년 생입니다만 우리 시절에는 미적분이 너무나도 어렵게 문제가 나오는 바람에 수열과 통계 부분은 너무나 하찮게 다루어 버려서 아마도 지금의 제 나이 때 분들은 우리가 하려는 일에 대한 이해도가 그렇게 높지 않을 수도 있겠다는 생각을 하면서 이 글을 작성하고 있습니다.
이번 회차에서는 이전에 만든 5분 데이터와 이전 회차에서 만든 보조지표 클래스를 어떻게 사용하는 지에 대한 간단한 예시를 통해서 보조지표에 대한 아이디어를 제시합니다. 여러분들이 다른 아이디어를 첨가한다면 더 완벽한 전략을 만들 수도 있을 것입니다.
2. Condition Class 만들기
소스 내용(BithumbCondition.py)
import time as datetime
import pandas as pd
from addAuxiliaryData import Auxiliary
class BithumbTrading:
def __init__ (self, logger, base_balance, buy_condition, sell_condition):
self.logger = logger
self.base_balance = base_balance
self.buy_condition = buy_condition
self.sell_condition = sell_condition
self.ad = Auxiliary(self.logger)
self.df = None
def add_auxiliary(self):
self.ad.add_auxiliary(self.df)
def add_macd(self, short, long, signal):
macd, macdsignal, macdhist = self.ad.add_macd(self.df, short, long, signal)
self.df['macd1'] = macd
self.df['signal1'] = macdsignal
self.df['flag1'] = macd - macdsignal
def append_dataframe(self, df):
if df is None:
return
df=df.truncate(after=(df.index.max()-1)) #마지막 데이터는 짤라 낸다.
if(self.df is None):
self.df = df
else:
self.df = pd.concat([self.df, df], ignore_index=True)
if self.df is None:
return
self.df.sort_values(by='time', axis = 0)
self.df.reset_index(drop=True, inplace=True)
self.df = self.df.drop_duplicates(['time'], keep='first', inplace=False, ignore_index=True)
self.df.reset_index(drop=True, inplace=True)
self.logger.debug("add new data")
self.logger.debug(self.df)
def buy_scenario(self, index):
# print("buy_scenario max : %d : %d, return: %d" % (self.df.index.max(), index, self.buy_condition(index)))
return self.buy_condition(index, self.df)
def sell_scenario(self, index):
# print("sell_scenario max : %d : %d, return: %d" % (self.df.index.max(), index, self.buy_condition(index)))
return self.sell_condition(index, self.df)
def sell_and_buy(self):
self.origin_balance = self.base_balance # 초기 투자금 100만원
self.year_balance = self.origin_balance
self.balance = self.origin_balance
self.remains = 0
self.sell_balance = 0
self.unit_balance = 0
for i in self.df.index:
# print("수익률 계산 :%s" % datetime.ctime(df.loc[i, 'time']/1000))
self.close = self.df.loc[i, 'close']
time = self.df.time.loc[i]/1000
if (time % (365*24*60*60)) == 0: # 1년에 한번씩 년간 수익률을 계산하기 위해서
# print("unit : %d" % self.unit_balance)
self.logger.debug(datetime.strftime('%Y년%m월%d일', datetime.localtime(self.df.loc[i, 'time']/1000)))
if self.unit_balance > 0 :
self.sell_balance = self.unit_balance * self.close
self.balance = self.balance + self.sell_balance
self.year_balance = self.balance
else:
self.year_balance = self.balance
self.logger.info("조정 원금: %.3f" % self.year_balance)
if self.buy_scenario(i) : #매수
self.sell_balance = self.balance - (self.balance % 1000)
# print("buy condition sell_balance: %.2f balance: %.2f unit: %.2f" % (sell_balance, balance, unit_balance))
if self.sell_balance > 0:
self.remains = self.balance - self.sell_balance
self.balance = self.remains
self.remains = 0
self.unit_balance = self.sell_balance / self.close
self.df.loc[i, 'balance'] = self.balance
self.df.loc[i, 'unit'] = self.unit_balance
elif self.sell_scenario(i): #매도
# print("sell condition close: %.2f balance: %.2f unit: %.2f" % (close, balance, unit_balance))
if self.unit_balance > 0:
self.sell_balance = self.unit_balance * self.close
self.balance = self.balance + self.sell_balance
self.unit_balance = 0
self.sell_balance = 0
self.df.loc[i, 'balance'] = self.balance
self.df.loc[i, 'unit'] = self.unit_balance
else:
self.df.loc[i, 'balance'] = self.balance
self.df.loc[i, 'unit'] = self.unit_balance
if self.year_balance != 0:
self.df.loc[i, 'year_rate'] = ((self.df.loc[i, 'unit'] * self.df.loc[i, 'close'] + self.df.loc[i, 'balance']) - self.year_balance) * 100 / self.year_balance
else:
self.df.loc[i, 'year_rate'] = 0
self.df.loc[i, 'rate'] = ((self.df.loc[i, 'unit'] * self.df.loc[i, 'close'] + self.df.loc[i, 'balance']) - self.base_balance) * 100 / self.base_balance
return self.df첫줄에 time lib를 import 하면서 이름을 as로 datetime으로 변경했습니다. 이유는 pandas에서 컬럼명을 attribute형으로 사용하는 경우가 있는데 이때 우리 데이터 중에 time이 있어 혼돈이 있을 것을 대비하여 변경했습니다. 위 소스는 백테스팅을 고려해서 만든 것이라 지금은 당장 사용하지 않는 부분들도 포함이 되어 있습니다.
자 그럼 main.py를 변경하여 데이터를 연동하도록 하겠습니다.
소스내용(main.py)
from getBithumbData import ScrapCurrBithum
from BithumbCondition import BithumbTrading as BitTra
import time as datetime
import sqlite3
import logging
import logging.config
import json
config = json.load(open('./logging.json'))
logging.config.dictConfig(config)
buy_func = lambda x, dataframe: (x >= 2 and dataframe.loc[x, 'flag1'] > 0 and dataframe.loc[x-1, 'flag1'] <= 0 and dataframe.loc[x-2, 'flag1'] <= 0)
sell_func = lambda x, dataframe: (x >= 2 and dataframe.loc[x, 'flag1'] <= 0 and dataframe.loc[x-1, 'flag1'] > 0 and dataframe.loc[x-2, 'flag1'] > 0)
BASE_BALANCE = 1000000 # 초기 투자금 100만원
if __name__ == '__main__':
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
dbname = "bithum5mMACD1.db"
sqlcon = sqlite3.connect(dbname)
bt = BitTra(logger, BASE_BALANCE, buy_func, sell_func)
scb = ScrapCurrBithum()
last_time = ""
while True:
start_time = datetime.time()
df = scb.get_data()
bt.append_dataframe(df)
#전체 보조 지표를 포함하지 않고 개별 보조 지표를 사용하도록 하겠습니다.
#bt.add_auxiliary()
bt.add_macd(12, 26, 9)
df = bt.sell_and_buy()
savedf = df.tail(1)
get_time= datetime.strftime("%Y%m%d%H%M%S", datetime.localtime(savedf.loc[savedf.index.max(), 'time']/1000))
if last_time == "":
df.to_sql(name=dbname, con=sqlcon, if_exists='replace')
elif last_time != get_time:
last_time = get_time
savedf.to_sql(name=dbname, con=sqlcon, if_exists='append')
logger.info("MACD1 최종:")
logger.info(df)
strdt1 = datetime.strftime("%Y%m%d", datetime.localtime(df.loc[df.index.max()-2, 'time']/1000))
strdt2 = datetime.strftime("%Y%m%d", datetime.localtime(df.loc[df.index.max()-1, 'time']/1000))
logger.info("마지막1전: %s, 마지막:%s", strdt1, strdt2)
if(strdt1 != strdt2 ): #날짜가 변경되었다면
logger.info('자정이면 메모리를 일부 크리어한다.')
df = df.tail(df.index.max() - 12*24)
df.reset_index(drop=True, inplace=True)
end_time = datetime.time()
if (end_time - start_time) > 0 and (end_time - start_time) <= 5*60:
datetime.sleep(5*60 - (end_time - start_time))
sqlite3을 이용하여 수신 데이터를 DB에 저장하므로 우리가 만든 폴더에 "bithum5mMACD1.db" 파일이 생성되었음을 확인할 수 있을 것입니다. 이 회차에서 가장 어렵고 중요한 부분은 "append_dataframe" 함수입니다.
이전에 만든 getBithumbData.py에서 close와 volume은 float형으로 값을 변경했지만 time은 값을 변경하지 않았습니다. 이유는 time은 RDBMS의 key처럼 동작 하지만 우리가 주로 사용하는 intel cpu의 경우 부동소수점의 값은 "그때그때 달라요" 값입니다. 즉 float형을 key값으로 사용하면 여러분의 데이터는 유일성을 보장할 수 없습니다. 하지만 python은 어떤 면에서는 데이터형 검사가 엄격해서 정수형 데이터로는 어려운 수식 계산 시 오류가 발생합니다. 내용을 쭉 읽어 보면 double 형 데이터가 아니어서 계산이 불가하다는 내용입니다. python을 쉽게 봤던 사람들은 여기서 멘붕에 빠지게 됩니다. 참 그리고 우리가 받고 있는 Bithumb의 5분 데이터는 실제는 1주일치 데이터이며 마지막 한 줄은 "완전 실시간" 데이터입니다. 그러다 보니 마지막 한 줄이 보조지표의 정확성에 방해가 됩니다. 보조지표의 대원칙은 간격이 일정해야 하고 유일성이 보장되어야 합니다. 그렇지 않으면 계산은 아무런 의미가 없습니다.
3. DB 파일 보기 (https://sqlitebrowser.org/dl/)
제목 옆에 링크를 클릭하시면 sqlitebrowser를 다운 받을 수 있는 사이트로 접속합니다. 거기서 자신에게 맞는 버전을 다운로드하시고 설치하시면 DB파일을 볼 준비가 완료됩니다.
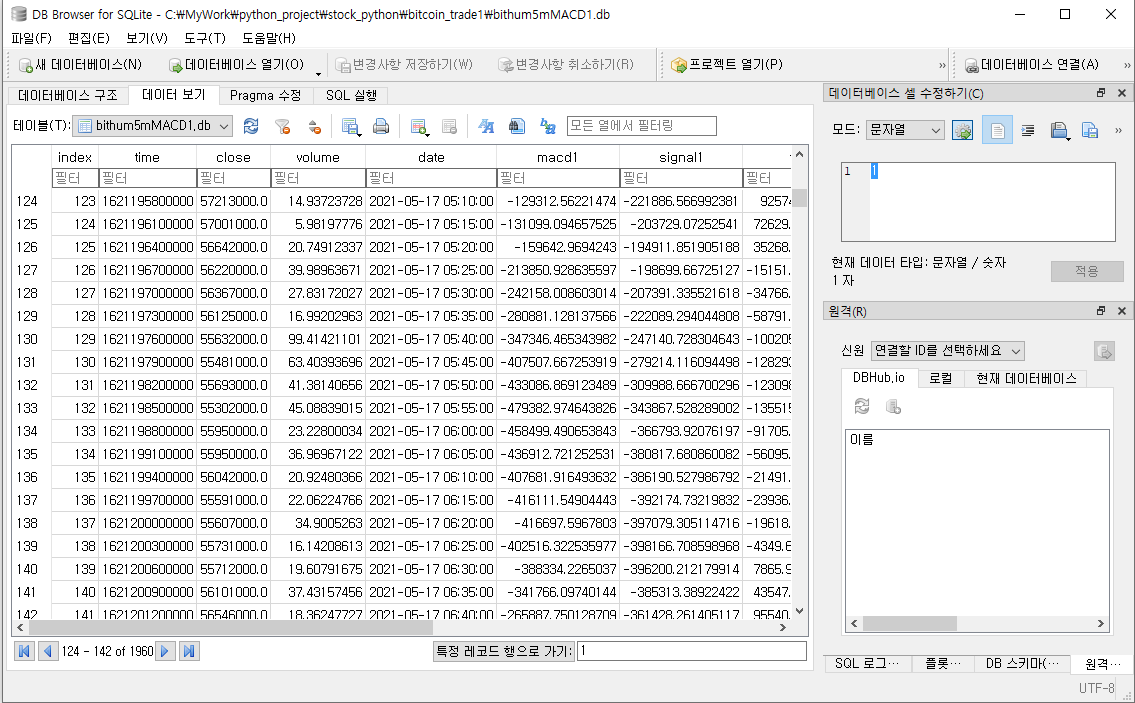
DB Browser를 실행한 다음 File--> 데이터베이스 열기-->해당 폴더의 db파일 지정하시면 위와 같이 DB파일을 보실 수 있습니다. 2021년 오늘 시점 일론머스크의 발언과 미정부의 자본세 발표 및 우리나라도 비트코인 규제 방침이 발표되면서 시장이 급락하고 있습니다. 마지막 컬럼 두 개가 일 년 수익률과 전체 수익률입니다. 현재 -16.7%를 기록하고 있네요. ^^
4. 데이터 분석
DB Browser에서 File-->내보내기-->CSV로 내보내기를 선택합니다. 같은 폴더에 bithum5mMACD1.csv로 파일을 저장합니다. Excel을 실행하여 csv파일을 엽니다. 그리고 MACD가 처음 시작하는 32행까지를 삭제하여 데이터를 정리 합니다. shift키를 눌은 상태에서 close컬럼과 flag1컬럼을 선택 합니다. 그다음 삽입에서 차트를 삽입합니다. 차트를 클릭하면 메뉴에 차트 디자인이 보일 겁니다. 차트 디자인에서 차트 종류 변경을 클릭합니다.

그럼 아래 차트가 만들어집니다.

이번에는 close컬럼과 macd1, signal1컬럼을 선택하고 데이터 범위를 하루치(12X24=288)만 선택하여 차트를 만듭니다.
그리고 차트 디자인에서 아래와 같이 클릭하고 확인을 클릭합니다.

아래의 차트를 보면서 데이터 분석을 해 보도록 하겠습니다.

먼저 오늘 데이터 연동을 하면서 적용한 보조지표는 MACD입니다. MACD는 단기이평선과 장기이평선이 서로 만났다가 떨어지고 다시 만나는 반복되는 상황에서 macd값이 상위에 있으면 매수 macd선이 하위로 오면 매도를 하게 프로그램하면 됩니다. 마지막 차트를 보면 거의 정확한 시점에서 매수와 매도가 발생하고 있음을 알 수 있습니다. 그럼에도 불구하고 전체 수익률은 -15~-17%사이를 움직이고 있습니다. 이는 macd의 약점 중에 하나인 허매수 신호가 발생하고 있기 때문입니다. 허매수 신호는 완전 폭락이 발생하는 구간보다는 옆으로 흔들리면서 이동하는 구간에서 많이 발생하고 있음을 차트로 알 수 있습니다. 전문가들이 macd의 가장 큰 약점이라고 하는 후시성은 위에 차트에서도 알 수 있듯이 5분 데이터에서는 큰 영향이 없습니다. 오히려 급락 구간을 잘 피해서 매수를 하고 있음을 알 수 있습니다. 그리고 급등 구간에서도 매수가 되어 큰 성과를 내고 있음을 알 수 있습니다. 그렇다면 flag값은 무엇일까요? MACD Oscillator라고도 하는 값입니다. 이 값이 양수이면 매수 이 값이 음수이면 매도를 하면 되기 때문에 프로그램에서 매수매도를 구현하기가 쉽습니다. BithumbCondition.py에 BithumbTrading class에 들어가는 lambda 함수 식의 의미가 바로 flag를 기준으로 매수 매도를 하는 공식입니다.
5. 마치며
오늘 회차는 어떠셨나요? 데이터 연동 및 차트 분석과 데이터 분석에 대하여 알아보았습니다. 그런데 아무리 하락장이라고 하지만 수익률이 너무 심하지 않나 싶을 겁니다. 우리의 목표가 여러 보조 지표를 활용해서 기대 수익률을 낮추면서 하락장에서 수익률을 잃지 않는 프로그램 개발이라는 것을 잊지 마세요. 오히려 지금과 같은 과하락장이 우리 프로그램에는 좋은 기회입니다.
'python > 자동매매 프로그램' 카테고리의 다른 글
| python Bitcoin 자동 매매 프로그램(6) - 나의 Bithum API 극복기 (1) | 2021.08.05 |
|---|---|
| python Bitcoin 자동 매매 프로그램(5) - 파도와 바람 (7) | 2021.07.25 |
| python Bitcoin 자동 매매 프로그램(4)-Bithumb 연동 (0) | 2021.05.30 |
| python Bitcoin 자동 매매 프로그램(2) - 보조 지표 구하기 (0) | 2021.05.23 |
| python Bitcoin 자동 매매 프로그램(1)-데이터 얻기 (0) | 2021.05.23 |