![]()
import random
from collections import deque, namedtuple
from typing import Dict, List, NamedTuple, Optional, Text, Tuple, Union
from IPython.display import display, Math
from Account import Account
import math
from itertools import count
import os.path as path
import numpy as np
import plotly as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from Market import Market
from PIL import Image
from plotly import express as px
import torchvision
import time
import joblib
import sys,os
action_kind = 4
max_episode = 5000
screen_height = 50
screen_width = 70
visit_cnt = [0] * action_kind
# replay_buffer = deque()
epsilon = 0.3
dis = 0.9
data_size = 600
BATCH_SIZE = 8
GAMMA = 0.999
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 200
TARGET_UPDATE = 10
steps_done = 0
loss = any
# for i in range(torch.cuda.device_count()):
# print(torch.cuda.get_device_name(i))
# if gpu is to be used
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# device = torch.device("cuda")
# device_str = "cpu"
device_str = "cuda"
device = torch.device(device_str)
from dqn import DQN
converter = torchvision.transforms.ToTensor()
market = Market()
policy_net = DQN(device, screen_height, screen_width, action_kind, 32).to(device)
policy_net = nn.DataParallel(policy_net, device_ids=[0,1]).to(device)
def get_chart(market, idx, max_data):
# img = Image.fromarray(np.uint8(cm.gist_earth(plt.io.to_image(fig, format='png')*255)))
# im = Image.fromarray(img, bytes=True)
# im = Image.fromarray(np.uint8(cm.gist_earth(img))/255)
# im = Image.fromarray(np.uint8(img)/255)
# img = img.resize((700, 500), resample=Image.BICUBIC)
# display(img)
# img = Image.fromarray(cm.gist_earth(plt.io.to_image(fig, format='png'), bytes=True))
img = market.get_chart(idx, max_data=max_data)
img.convert("RGB")
# print(img)
img.thumbnail((screen_high, screen_width), Image.ANTIALIAS)
return chart
def plot_durations(last_chart, curr_chart):
plt.figure()
# plt.subplot(1,2,1)
img = plt.imshow(last_chart.cpu().squeeze(0).permute(1, 2, 0).numpy(), interpolation='none')
plt.title('Example extracted screen')
plt.figure(2)
# plt.subplot(1,2,2)
plt.clf()
# durations_t = torch.tensor(episode_durations, dtype=torch.float)
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Duration')
# plt.plot(durations_t.numpy())
# plt.show()
# Take 100 episode averages and plot them too
# if len(durations_t) >= 100:
# means = durations_t.unfold(0, 100, 1).mean(1).view(-1)
# means = torch.cat((torch.zeros(99), means))
# plt.plot(means.numpy())
img.set_data(curr_chart.cpu().squeeze(0).permute(1, 2, 0).numpy())
plt.pause(0.01) # pause a bit so that plots are updated
# if is_ipython:
display.clear_output(wait=True)
display.display(plt.gcf())
def select_action(df, idx):
return ((df.loc[idx, "close"] - df.loc[idx, "closemin"]) * (action_kind-1) // (df.loc[idx, "closemax"] - df.loc[idx, "closemin"]))
def main():
if path.exists("pt/train_net_{}.pt".format(device_str)):
policy_net.load_state_dict(torch.load("pt/train_net_{}.pt".format(device_str)))
policy_net.eval()
for epoch in range(max_episode):
df = market.get_data()
account = Account(df, 50000000)
# account.back_up()
account.reset()
count = 0
correct = 0
last_chart = None
while last_chart == None:
last_chart = get_chart(market, data_size, data_size)
for idx, _ in enumerate(df.index, start=data_size + 1):
try:
since = time.time()
curr_chart = get_chart(market, idx, data_size)
if curr_chart is None:
continue
state = curr_chart - last_chart
curr_chart = last_chart
dqn_action = policy_net(curr_chart)
_,dqn_action = torch.max(dqn_action,1)
dqn_action = dqn_action.cpu().numpy()[0]
plc_action = select_action(df, idx)
count += 1
correct += 1 if dqn_action == plc_action else 0
print("idx:%d==>dqn_action:%d:%d, price:%.2f, match:%.2f"%(idx, dqn_action, plc_action, df.loc[idx, 'close'], correct * 100/count))
reward, real_action = account.exec_action(2 if dqn_action == (action_kind - 1) else (1 if dqn_action == 0 else 0) , idx)
reward = torch.tensor([reward], device=device)
real_action = torch.tensor([[real_action]], device=device, dtype=torch.long)
last_chart = curr_chart
if account.is_bankrupt():
break
spend = time.time() - since
print("idx:%d price [%.4f] unit[%.4f] used time[%.2f] agent rate:%.05f remind money:%.02f"
% (idx, df.loc[idx, 'close'], account.unit, spend, account.rate, account.balance + account.unit * df.loc[idx, 'close']))
except Exception as ex:
exc_type, exc_obj, exc_tb = sys.exc_info()
fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]
print("`epoch loop -> exception! %s : %s %d" % (str(ex) , fname, exc_tb.tb_lineno))
# torch.save(policy_net.state_dict(),"pt/policy_net.pt")
# print("epoch[%d] epsode is next loss[%.05f]" % (epoch, loss.item()))
if path.exists("pt/train_net_{}.pt".format(device_str)) and epoch % 100:
policy_net.load_state_dict(torch.load("pt/train_net_{}.pt".format(device_str)))
policy_net.eval()
# if loss.item() < 0.00001 :
# break
print('Complete')
if __name__ == "__main__":
main()오늘은 강화학습으로 pt파일이 만들어졌다면 그것을 이용하여 실제 매매이전에 back test를 진행하는 main_agent.py에 대하여 말씀 드리겠습니다.
get_chart() 함수를 이용하여 torch.tensor로 변환된 PIL 이미지를 받습니다.
최초 실행시 0번 이미지를 미리 받아 두고 0번 이미지와 1번 이미지의 차를 구합니다.
이것이 강화학습에서 말하는 상태 S1이 됩니다.
시간 t1에 대한 S1이 생성되면 이것을 DQN에 넣고 행동 a1을 받습니다.
a1은 0,1,2 중 하나의 값입니다.
0은 관망 1은 매수 2는 매도를 하게 됩니다.
앞 장에서 다룬 내용중 Markget.get_data()함수의 데이터 갯수를 줄이거나 늘려서 매매 횟수를 변경할 수 있으며 epsilone 값을 변경 하면 매매프로그램이 얼마나 자주 모험적인 선택을 할지를 결정 할 수 있습니다.
학습에 사용된 pt/train_net.pt 파일은 학습 및 응용과 지금 main_agent.py에서도 공유됩니다.
공유된 DQN의 하이퍼 파라메트에 의해서 main_agent.py는 훈련 없이 바로 detection이 가능합니다.
실제 실행 되는 상태를 보고 어느 정도의 수익이 발생하는 지를 과거의 데이터로 예상할 수 있습니다.
여기 발견된 오 작동이나 문제점은 main_buroto.py 파일의 recall_history()함수에서 반영되어 새로운 history Series 를 생성하여야 합니다.
새로 생성된 history를 이용하여 학습을 진행 하여 main_agent.py를 실행하면 학습된 내용은 자동으로 반영이 되겠죠.
학습 데이터는 작은 량에서 점점 큰 량으로 변화 시키면서 과적합이 발생하는지 확인 합니다.
학습이 정상적으로 이루어 지면 다시 main_agent.py를 실행하여 detection을 진행한다.
과거의 데이터를 이용하지만 DQN은 학습된 Q(s,a)함수를 실행하는 것이지 과거의 학습된 내용을 바탕으로 한 데이터를 따라 가는 것이 아니다.
실제 history내용과 비교 해 보면 그것을 알 수 있다.
아래 그림은 왼쪽은 과거 데이터를 이용하여 학습을 진행하고 학습된 모델을 이용하여 agent가 실행되는 모습을 담은 사진입니다.
agent가 6%대의 수익을 내고 있으며 학습하는 프로세스가 loss가 적어질 수 록 agent의 수익률은 조금식 증가합니다.
다음 시간에는 실전 매매 프로그램에 DQN 학습 모델을 연동하여 실시간에서는 어떤 동작을 하는지 알아 보겠습니다.


현재 학습이 진행되어 loss가 0.0221정도로 줄어든 로그입니다.
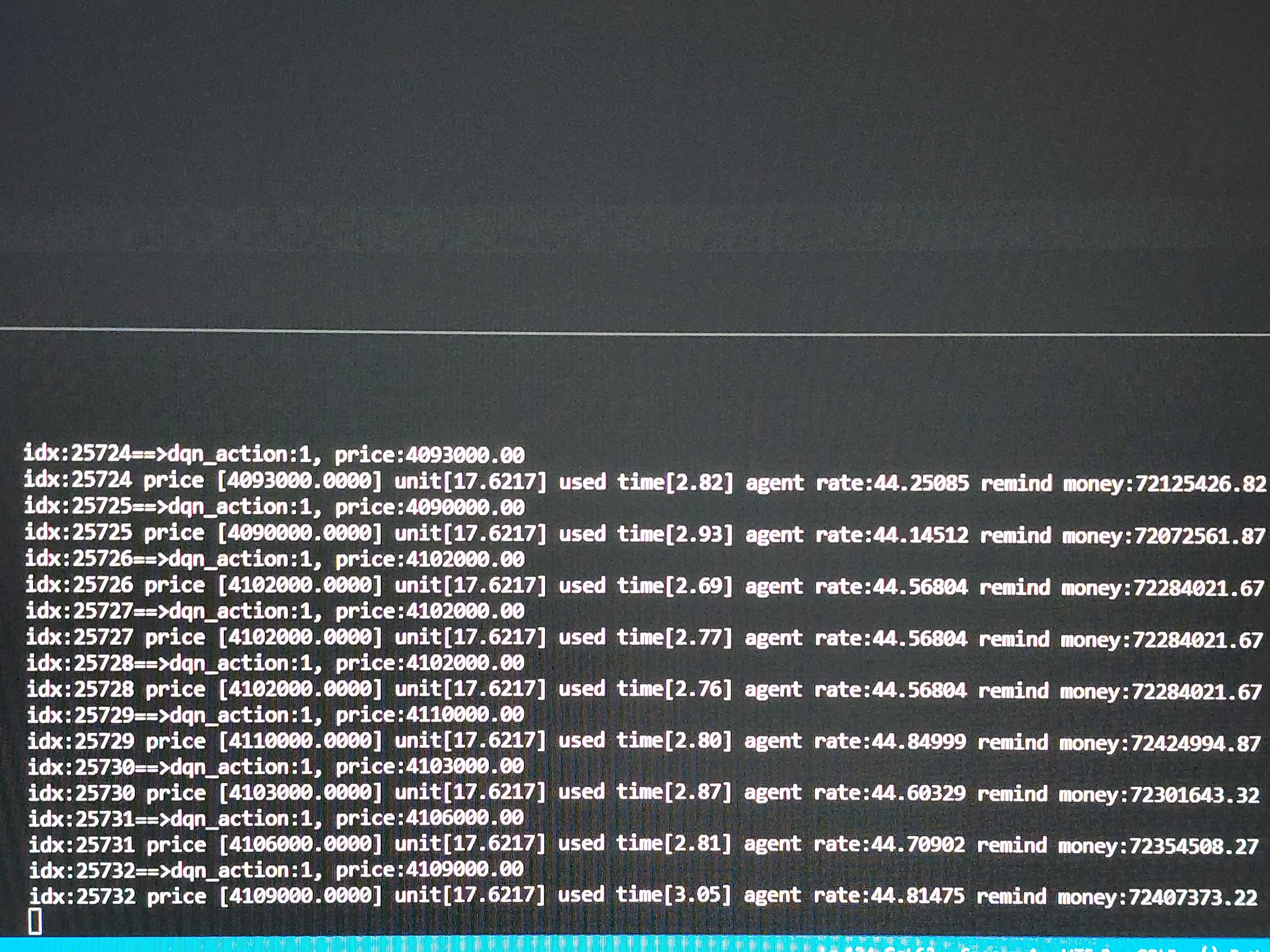
main_agent.py를 실행하면 학습된 training_cuda.pt파일을 읽어서 매매를 실행하여 테스트를 진행하는 사진입니다.
수익률은 44.81%정도 됩니다.
차트를 그리는 시간이 2초 이상걸려서 그리 빠르지는 않습니다.
하루에 약30000건을 테스트 중입니다.
개인 PC사양에 영향을 받을 것 같습니다.
'python > 자동매매 프로그램' 카테고리의 다른 글
| 강화학습을 이용한 비트코인 매매프로그램(12) - 실거래 적용 (5) | 2023.01.30 |
|---|---|
| 강화학습을 이용한 비트코인 매매프로그램(11) - ResNet + RNN 적용 모델 (1) | 2022.12.25 |
| 강화학습을 이용한 비트코인 매매프로그램(10) - CNN+RNN 모델 확장 (0) | 2022.12.21 |
| 강화학습을 이용한 비트코인 매매프로그램(9) - CNN+RNN 모델 (0) | 2022.12.20 |
| 강화학습을 이용한 비트코인 매매프로그램(8) - wsl이용하기 (3) | 2022.12.12 |